Index
- The Knowledge creation-application gap problem
- Segmenting a text based on the diversity of the retrieved documents from a knowledge base
- Colors and navigation
- Reading, studying, and writing with the colorful segments
- Future work
The Knowledge creation-application gap problem
When describing the The collaboration-information problem, I cited that I see an issue in collaboration because of the following gap:
I see a gap between knowledge creation and application. We fail to make knowledge relevant.
However, the same gap applies to individuals, and I cite it in the same article as a "Knowledge creation-application gap", which I started addressing using a Semantic Node Search for Org-roam.
It is the gap between how much information one gathers (what is information for you might be knowledge for others) and how much one applies it. I objectively feel this gap when I study something or formalize a concept I created or learned from others in Org roam, but I'm unable to apply it again in a new situation, which would configure the transition from information to knowledge or knowledge application.
Since the definition of information and knowledge depends on its usage, the two terms here can describe slightly different problems. The information-knowledge gap might refer to information that has never been transformed into knowledge by anyone, so we have a collective definition of information and knowledge. Or we can add the case in which it is knowledge for others who apply it, but it is still only information for certain individuals.
Like in the Semantic Node Search for Org-roam, I want to find ways that bring to usage my notes in the day-to-day.
I want to bring on more references because I feel good when I can (re)use concepts to solve new problems. It is how I see information becoming Knowledge. Even if unrelated to problem-solving, visualizing the connection between two things that might differ on the surface but share some underlying aspects, like a passage from a book I'm reading and a painting I saw in person when traveling a couple of years ago, is an end-goal sensation.
The semantic search demands me to proactively select a passage and check my references on it. Inspired by this post that plays with embeddings and colors, I had the idea to automatically break a file or region into chunks and then run the semantic search for every chunk. This segmentation problem is known as Discourse Segmentation.
Discourse segmentation is a field in Natural Language Processing (NLP) that involves breaking a text into logical elements of interest. It involves identifying the boundaries of the segments, which are marked by ponctuation, topic change, conjunctions, themes, etc. It is a subtask used for question answering, summarization, and sentiment analysis, for example.
Segmenting a text based on the diversity of the retrieved documents from a knowledge base
Considering the intention to go through text under the lens of my knowledge, I use a criterion based on the retrieved documents from the knowledge base made of my Org roam nodes.
It starts by splitting the text into sentences based on punctuation.

I point to the first sentence and consider it a candidate segment. Then I iterate over the sentences. In every iteration, I use my semantic search API to retrieve the top 15 documents related to the current segment and the following sentence. I compare the documents without considering their ranking or the hierarchy of the nodes. I check the percentage of overlapping documents.

With the overlapping percentage, I can decide whether or not to merge the following sentence into the current segment.
A parameter called segmentation granularity, which
ranges from zero to one, controls the merging decision by determining
the proportion of documents that must be similar to merge the sentence
into the segment.
When it is set to zero, the entire text will be a single segment, while using one will segment it by sentences—as we started. If I decide to aggregate the sentence into a segment, the next comparison is between the updated current segment (the previous "current segment" appended by the previous "following sentence") and the following sentence.
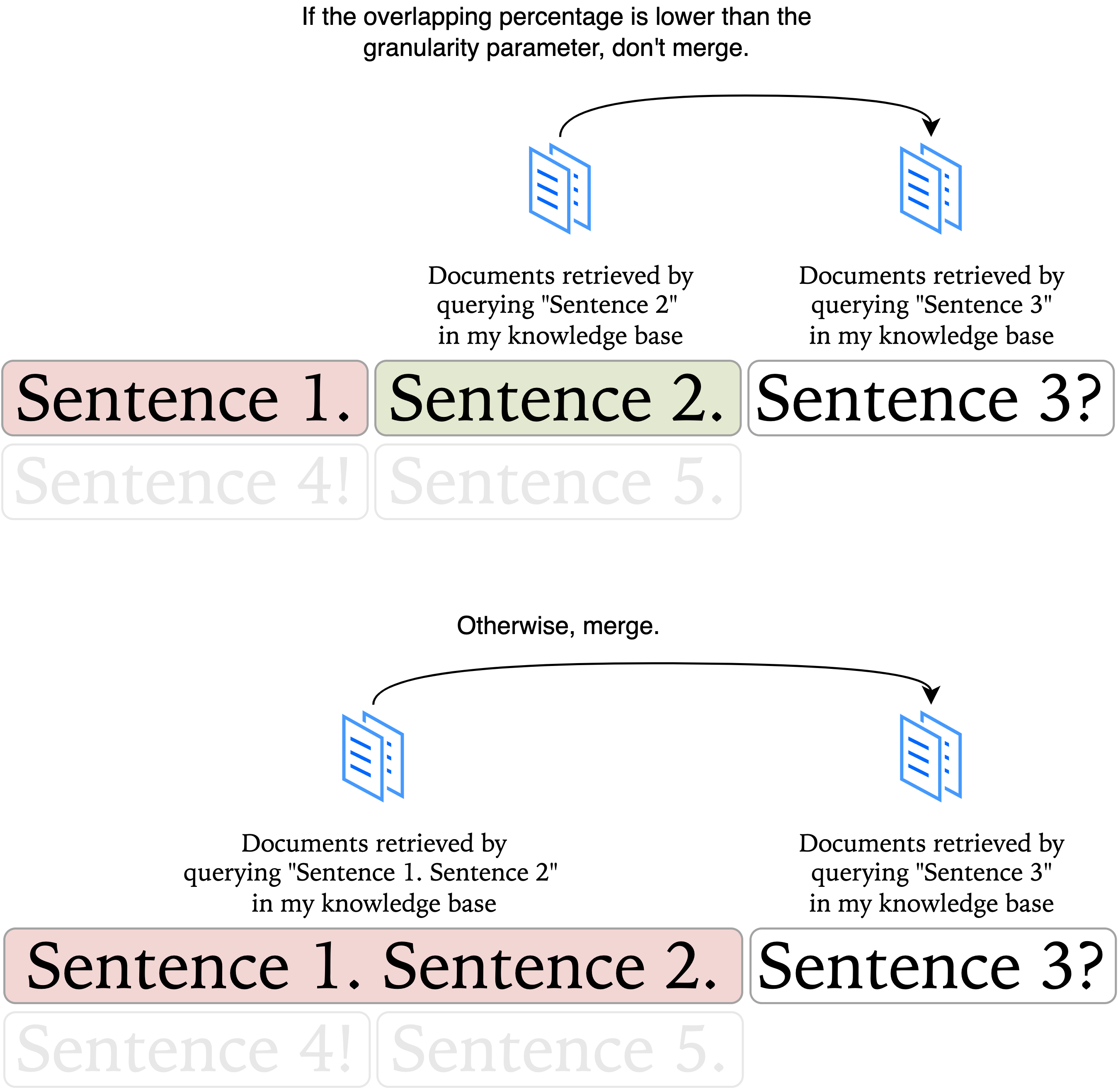
By the end, every sentence will have been grouped into a segment or become a segment itself.

This approach has the downside of the cold start problem since it depends on having a certain amount of notes to generate the comparison (I have 5k+). For example, if one has only 15 notes and retrieves the top 15, they will always overlap 100%, even though the notes might differ. Thus, it takes time to become interesting. During this phase, one can hardly segment by the diversity of one's knowledge.
One interesting behavior is that if you are just beginning to investigate a subject, the retrieved documents will be mostly the same, generating fewer segments. It makes sense that someone sees content in a subject they are a beginner with fewer nuances than those they have been in touch with for a longer time.
On the other side, considering the simplistic overlapping criterion, having many notes on the same subject is also harmful because comparing two segments can give a false sense of diversity if you have different notes that tackle very close subjects. A measure based on semantic distance might fit better here.
Here's the actual code. It is more convoluted than needed because I reuse the semantic search API, which could have a better interface. On the bright side, it is cool to build a new function based on it quickly.
Colors and navigation
I highlight segments using eight colors. It means the colors only differentiate segments but don't have a meaning per se. A color will appear multiple times in long texts but without interpretation.
I based the colors on flexoki,
but I modified them to look watered down in my background color. The
colors used in this post images are:
"#F4DBD9" "#E7EBD6" "#F6EDCD" "#F6E2D4" "#F3DBE5" "#D2DEF0" "#E1DCED" "#D7EBE9".
I use a minimalistic theme, and the colors bring more sense into my activities than a distraction. I don't keep the highlights. A function clears them out when I finish reading or writing. Making them look beautiful and minimal was critical. It is a small pleasure that compounds in my activities—just as specific pens provide extra pleasure in handwriting, the paper color and granularity attend to our touch in physical book reading, or keyboards offer tactile fun to typing.

I the segmentation to take me to a state that feels exploratory and
dynamic. So, I used ivy-pos-frame to bring similar
documents when I use a shortcut over a segment. I can quickly navigate
on it and open the Org roam node by hitting RETURN. I keep
the menu and the cursor position on it even after opening a node to
enable going to another node quickly. See below the new buffers popping
up, then getting replaced by the new references I open, which enables me
to skim many of my notes seamlessly. The elisp
code.
I wonder if a navigation mode would make it even better. It is,
moving from one segment to the other by only pressing n or
p, automatically displaying the top results. Or simply use
C-c n and C-c p to navigate the segments. It
would certainly save me time, and it would be perfect for reading.
I can easily set the granularity parameter to change my experience.

I've been using it mostly to give me something that connects three meaningful sentences in the same segment and isn't simply segmented by paragraphs.
Reading, studying, and writing with the colorful segments
Though my initial motivation was writing, I realized that reading implies writing to me most of the time. When reading books, blog posts, scientific papers, etc., I will take notes even if it is a single paragraph about a concept I've learned from it, or to say why I didn't engage much in note-taking for it.
In the beginning, I copied and pasted text into the Emacs scratch buffer to apply the function, but now I'm slowly bringing content directly to it to streamline the process. Two working solutions are Emacs Web Browser (EWW) for web content and nov.el for epubs.
All the above examples on top of Machines of loving grace are in EWW.
I'm not a big fan of reading on an LCD screen. Ny book reading still happens on Kindle. I highlight and write Kindle notes, and when I finish or do a checkpoint, I export my Kindle notes to the bibliographical notes in org roam, where I keep it under a heading called "Kindle highlights", and I go over them extracting the notes, re-reading, and processing it into new nodes. Nonetheless, when skimming The Timeless Way, Alexander (1979), I had a passage connected to a piece of creative writing I did over 10 years ago. Revisiting it and grasping the resemblance satisfied a need orthogonal to productivity and nudged me into contemplation.
When writing, I apply it to org roam content. I navigate the segments and check for links. Then, eventually, I link written ideas to nodes representing them or add more ideas revealed by the connections. Finally, I use a function to clear the colorful faces and keep editing.
Future work
The joint activity of reading, thinking, contrasting with my knowledge, linking what I'm learning to what I know, writing and explaining new concepts with my own words, and applying it to learn is the real day-to-day activity I do and enjoy. This functionality gives me more structure to better enjoy the transitions between these activities. I see it as a feature for "fixing books" as in Andy Matuschak's Why books don't work.
I'm working on functionality to support the contrast of my knowledge to the new content, ease the links, and engage me in thinking. I am curious to formalize why I connect two nodes when writing. I realized I do it so automatically that I have to think to answer if one idea is composing the other or if I'm opposing or reinforcing them. I hope to write about it here.
As a closing remark, if you have read the Sharing
content with Org Roam post, this text is another example of writing
inside Org roam. By the way, the first section is made of two
transclusions. The Org nodes are: The knowledge
creation-application gap and Chunkfy semantic
search. For the second one, I wanted only the heading called
"Problem statement", which isn't an Org roam node, so I could link its
content using
#+transclude: [[file:20241224080942-chunkfy_semantic_search.org::*Problem statement][Chunkify Problem Statement]] :level 2 :only-contents.
It engaged me in improving the text to make it modular enough to be
transcluded, which is another thing I classify as cognitive joy.
