Index
- Why to refactor and the new capabilities
- The modular assistant
- User profile
- Quality of the interactions
- Sessions
- Development
- Future work
Why to refactor and the new capabilities
Previously, I talked about my personal assistant that uses my Org agenda view, to-do org file, and Org-roam files as context to interact with me on Emacs and provide proactive assistance using pre-defined routines. I continued using it and discovered that interacting directly with it via chat was a rare occurrence for me. Additionally, I found that the previous approach, which relied on a chain of LLM calls, was not easy to evolve. I hypothesize that I mostly benefit from the assistant's proactive notifications because it was hard to extract value from something that talked generically about my tasks and goals.
This isn't exactly a surprise to me since the 90 days I had with the previous version were enough to conclude it:
I mapped a second large iteration, in which I will use agents and tooling instead of chains. The idea is to better isolate use cases and get closer to useful modules by providing more structure.
This post is about the second iteration. It has many novelties, including agents, third-party agent tools, OpenAI Agents SDK, LangSmith, a Web UI, user profile, sessions, insights, user intents, and an org roam node link recommendation system.
The modular assistant
From the first version's chain, I moved to use LangGraph to organize the agents in my system. The modularity agents provide is helpful in two ways:
- I can add new agents and let an intent classifier pick them when they are the best option to solve a query. Since I do intent classification after every message and share the conversation history, one agent can use the output of the other and keep the conversation.
- I can direct routines to be executed by a specific agent and craft something very good for particular use cases.
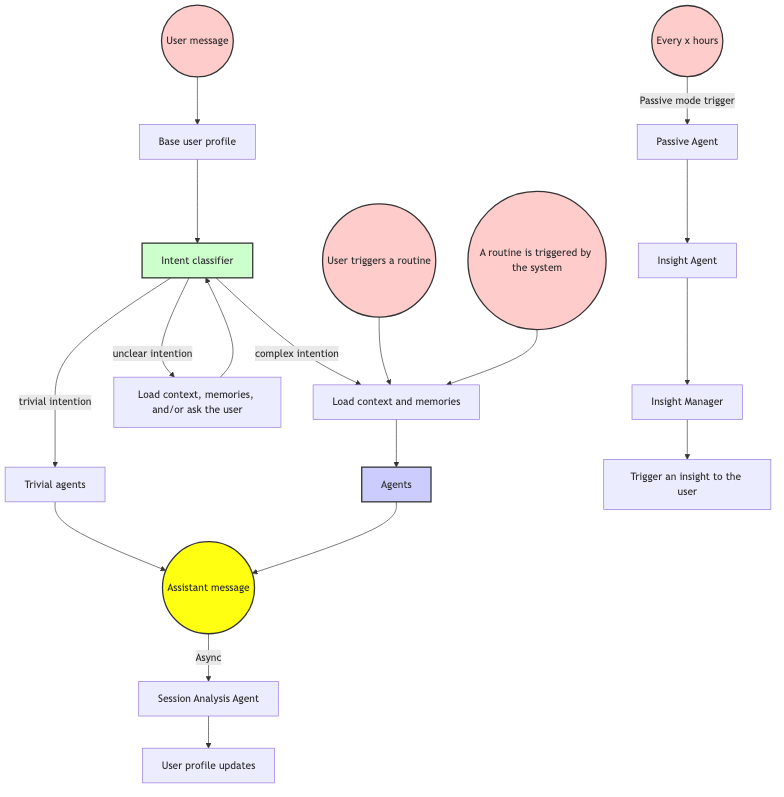
This modularity is very cool because I can add use cases without
compromising the remaining behavior. If I want to ensure a certain
situation gets handled by a specific agent, I can simply build a new
agent, a new user intent class, and route the requests to it directly
based on that situation. For example, I have routines for requesting a
review from a specialist researcher, allowing me to select from multiple
fields. These requests now go to the researcher_agent. It
has the right tooling: arxiv search, web search, org roam recommender
system, and org roam semantic search; so it is more predictable that it
will deliver the essential elements I want for the use case. Previously,
it was just a prompt going to the same "main agent".
To be more precise, adding a new class to the user intention can have an effect in other cases because the basic flow now can route to that new intent, which is solved by the new agent. So far, the use cases are so different that it hasn't happened.
I haven't tackled latency yet, and complex intentions typically take 15-40s to respond, which is quite lengthy. The only thing I did to reduce it was to create a trivial intention, which identifies greetings, salutations, and small talk in general, so it doesn't need to fetch context, and it can use a cheap and fast LLM.
After every interaction in a session, an agent is called to analyze it asynchronously. It will read the conversation history, provide a title for the session, generate a summary, and create a list of things it learned about the user. I provide more details about what a user profile is and what updating it means in the following section.
Insights have a different execution graph and trigger. It is time-based to ensure I'm not accumulating activity. Everything I do becomes context. Recalling from the V1 post: all editions of my personal to-do file, my agenda view (based on the to-do file), and each edition I do to almost any of the 5.4k Org Roam nodes I have become context to be reviewed. The passive agent will look at that event without a user query and summarize what the user is doing. I will provide more details about how insights are generated in one of the following sections.
User profile
A new feature I'm playing with is creating a minimal user profile that the assistant has access to in every session, regardless of the specific agent, so answers feel more personalized. I was inspired by you.com and the Dia browser.
I'm experimenting with two approaches: letting the user define the
profile and letting the assistant learn it. I can freely edit my profile
using the web UI. Still, after every conversation, the
session analysis agent will try to extract useful
information to personalize future interactions and edit my profile
proactively. In the image below, the entry in the
current_projects was filled automatically.
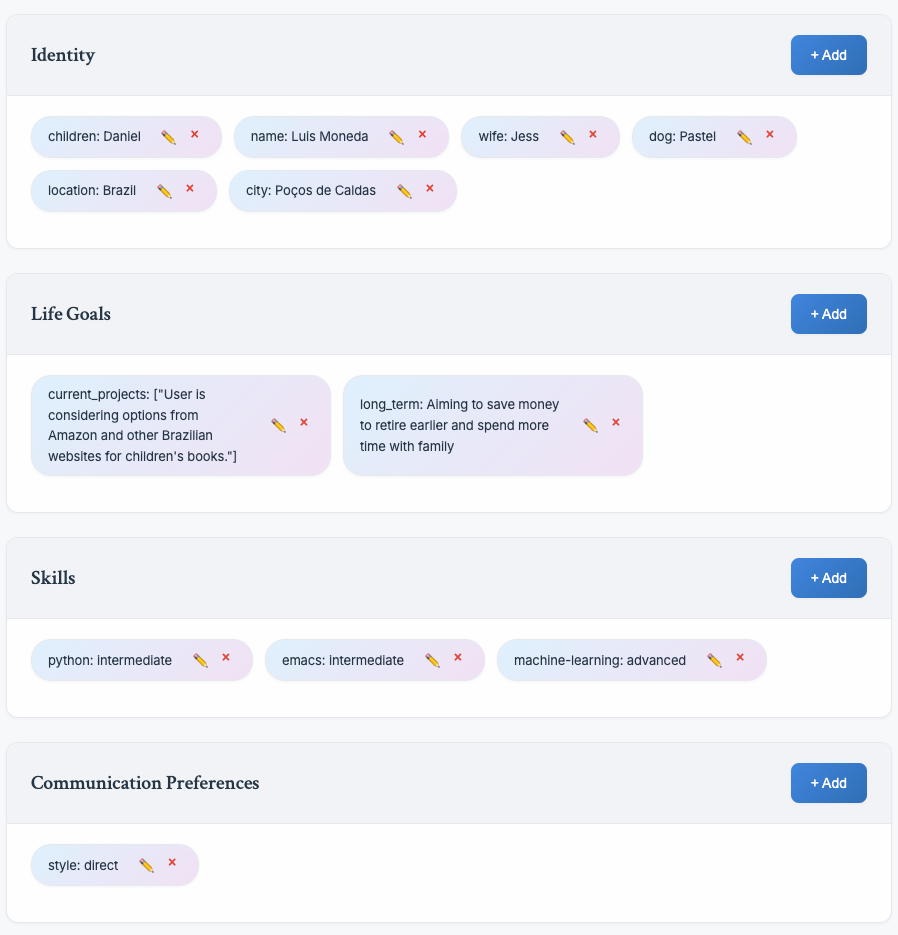
I recall adding "juggling" as a skill to check how much the assistant would leverage it. It made every answer a pun about it, so it was forcing it too much. Lately, I'm unsure why it isn't forcing the current profile values in every interaction. The example below is interesting, though I know it is a bit cherry-picking. It knows where I live, so the answer considers my city's attractions; it also relates to items in my to-do list (the nutricionist, physical evaluation, and the "banana chocolate recipe"), and it leverages the family relationship when suggesting a spa day for my wife so I can have some time together with my son.
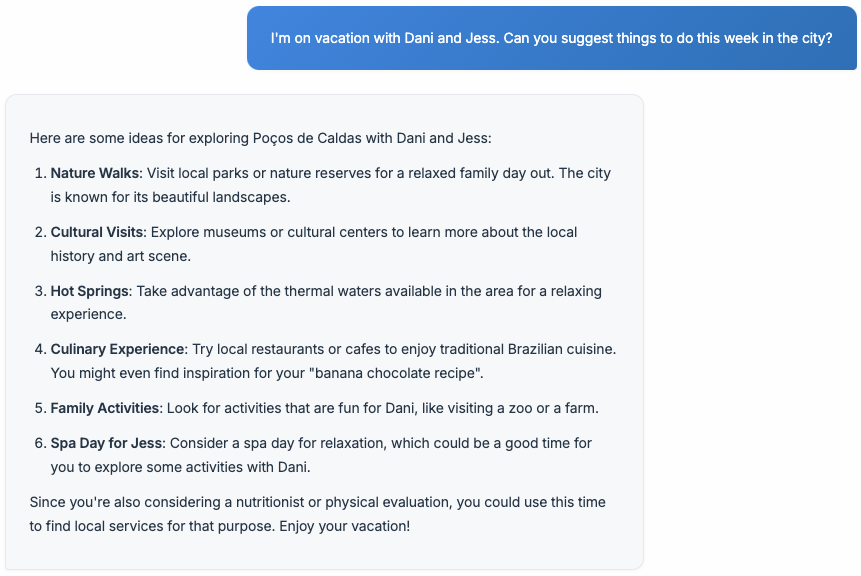
I will explore memory in ways beyond its current scope. I want it to be able to recall more information about the entities cited in the text. Although it includes a memory retrieval step that may bring up conversations I had about Dani or Jess, I'd appreciate it if it could retrieve information more systematically about a specific person, goal, or topic.
Furthermore, I had expected it to suggest more specific details in the previous example. Why not suggest a specific local park? Why not recommend a list of actual restaurants? It has the web search tool, but I need to follow up with a message to get specific recommendations.
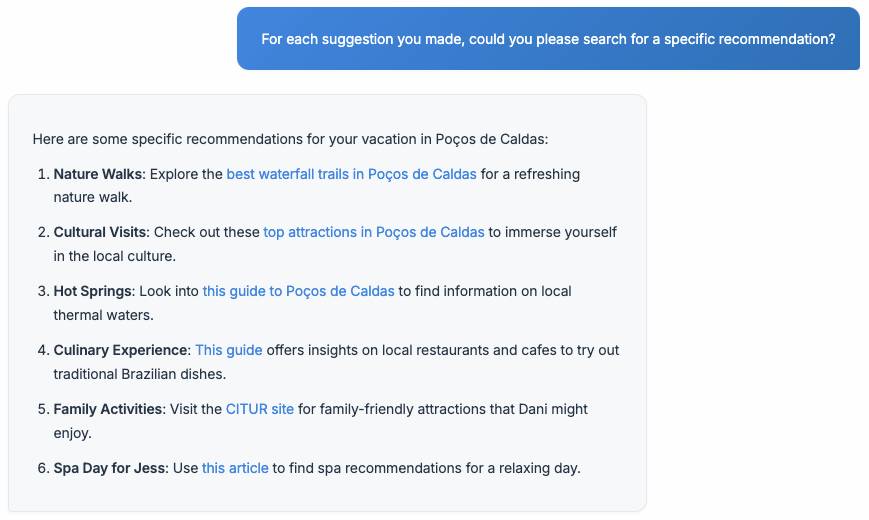
When producing the above example, I noticed I didn't equip the main
agent with web navigation, only web search. Then, I just added
playwright web navigation as a tool, and below you see it
could extract the needed information to generate specific information.
At the same time, it hallucinated beautifully by recommending "Claude
Flow Experience" based on a to-do item I have for this week about
experimenting with Claude Flow, an AI programming tool. The link it uses
is the reference link from my to-do item.
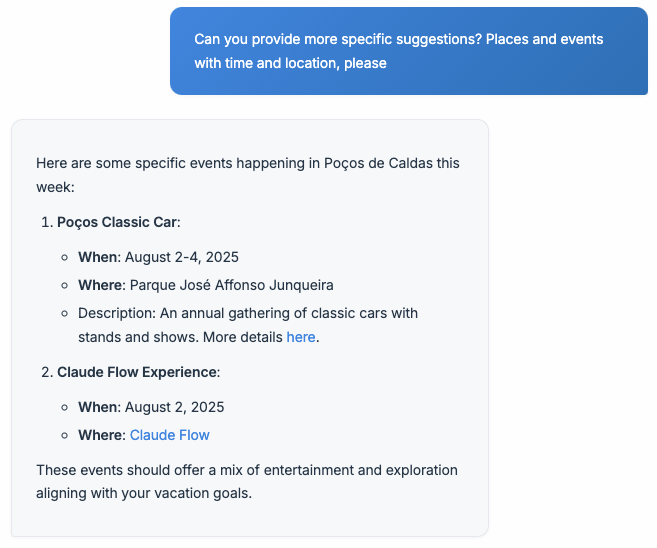
Demanding more details about the event retrieved the expected result. Today, visiting a website and extracting information is a very basic thing for LLM applications. Still, I highlight how easy it was to fix the absence of this ability in the main agent.

Quality of the interactions
Routines
Routines are still the way I interact the most with my assistant, mainly proactive routines. Currently, I have three proactive routines: morning outline, continuous review, and evening close. They all have some logic to trigger proactively: in a range of morning hours, every 2 hours to check changes in my org roam files, and at 5:30 pm.
All of them are handled by the main agent yet. However, I am already considering creating a "reviewer agent" to invest in providing structured reviews, such as tooling for grammar check, and offering textual changes that I can accept and replace text.
What is an insight?
Insights are proactive interactions that are produced by an insight agent, which accesses analysis of all the proactive interactions and the logs coming from the passive agent, that analyzes my behavior even when I don't interact with the assistant. Insights are delivered by an insights manager who looks into a list of insights and decides which to deliver, postpone, or ignore.
Let's review some insights:
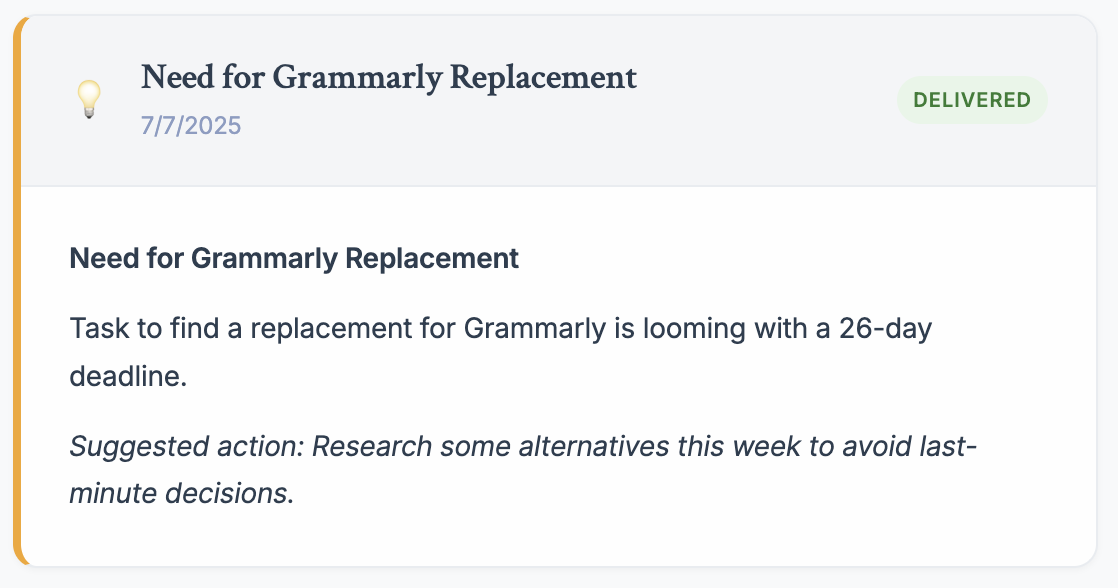
This is a very mundane thing based only on my agenda view that shows a deadline for a task. It is cool to have my attention drawn to it - I think I wasn't scheduling time for the replacement before seeing it, but it is also very operational, so I'd prefer to have it as part of my current routines. I mean, if I always want to be warned about deadlines that are not connected with tasks to make the activity happen, I can't rely on the insights but rather have a specific routine that checks for it.

This insight was particularly interesting because it drew from a conversation I had with my assistant about organizing family vacations, the many items I have about personal work, and finding out activities for my son. It highlighted that work-life balance was a delicate balance and encouraged me to pay closer attention to it.
Now, let's examine the reasoning behind the insights manager's approach. Here's an example of an insights manager's reasoning. The numbers are the insights' IDs:
Manager reasoning: Insight 48 is highly relevant as Luis is currently focusing on early retirement and long-term goals, making it a priority to create a timeline. Insight 46 should be delivered as it aligns with his current focus on tech leadership skill development. Insight 45 is postponed as AI task management tools can be introduced after structuring the retirement goals. Insight 43 is postponed because reflection can be tackled after immediate goals are addressed. Insights 47, 44, 42, 41, 40, 38, and 35 are ignored as they are either redundant, less relevant, or address issues not currently prioritized by Luis.
I certainly need to work more on this to make it useful for crafting a good insight management.
Nonetheless, I don't think I have a good frame for the insights feature yet. Currently, I expect insights to be surprising and interesting. However, since I'm building this for myself, if I have a specific kind of analysis that's helpful, I would likely build a new routine. I could describe the outcome of my routines as "insightful" due to the interaction between the prompt, tools, and data from my work, but they remain limited by the decisions I made beforehand.
The current structure provides more freedom to the insight agent, so I can be surprised, but the results have been very underwhelming. So I still have conceptual work to do here, and then I need to think about a good structure to generate useful insights.
Finally getting references and org roam links right due to tools
Tools pushed quality to another level. I used to get broken links for my Org roam content, and it was really hard to get links to research papers when my assistant cited work, regardless of my insistence or capital letters in the prompts. Retrieving the links to my notes in the semantic search tool, Q&A tool, or the org-roam node link recommender system was extremely helpful in displaying them correctly. The Arxiv search tool does the trick for the research papers.
I had to work a little bit on the shopping assistant use
case to enable it to search the web, extract product links, and then
extract specific product information from two websites I usually buy
from, so it provides something that really saves me time. The tools
proved amazingly helpful in generating high-quality answers.
You have access to these tools:
brave_search: Find initial product search pagesget_product_links: Extract product URLs from search result pagesextract_product_info: Get detailed product information (price, rating, reviews)scrape_webpage: Extract general webpage content when needed
Sessions
Having sessions is a basic feature, but it enables something beyond the typical use of getting back to a conversation: continuing conversations initiated by the assistant. When I receive the result of a proactive routine call, I can click on the speech bubble in the top right and ask follow-up questions. The great thing is that all the context used to generate that message is part of the session, so it is natural for the assistant to justify the claims.

I still need to make the same thing for the insights. Since insights are generated from analyses of many different sessions, I'm unsure so far if providing the session used by the insights manager will be enough to generate a good follow-up interaction.
Development
For this version, I started using LangSmith for tracing and Aider for developing it. The combination of observability to spot what is not working as intended and AI programming tools was generally positive, but with some caveats.
Tracing was fundamental to spot silent failures: tools or sub-agents not working properly, and the LLM circumventing their error messages to send something ok, or using only the other available tools. It was also great to spot the bottlenecks, though I didn't focus on optimizing it yet.

memory_retrieval, including adding an agent, but I
realized it is taking too long.I also explored OpenAI's observability tool. It integrates automatically when using the OpenAI Agents SDK.
To complete the observability part, I also logged every step on the agents since it is difficult to spot where they are hanging when it happens. It was also very useful to copy and paste it to Aider.
For the AI programming part, I wouldn't have been able to refactor my assistant from LLM chains to an agentic version as quickly as I did. I also wouldn't have created a Web UI for it, which means I could skip a lot of tedious work and debugging. However, it had many bad moments since in many parts I wasn't following the changes made by the AI completely - I was vibe coding. After approximately 15 days of development (~2h/day), I reached a point where I could no longer add new functionality, and worse, including the non-working feature would break other things. At this point, I had to go through most of the generated code to acquire a deeper understanding. I requested regular AI tools like ChatGPT and Claude to do diagrams for individual files, and I manually coded the core fixes.
Nonetheless, I don't imagine doing any project that involves programming without this sort of tooling. I've been using ChatGPT for coding since its launch, and it is slower, but also more precise, since I had to break down problems before asking for a piece of the solution. These new tools (Aider, Cursor, Claude Code) are certainly more powerful, but require slightly different skills and better anxiety management to keep your mental model of the project updated instead of developing more and more new stuff without fully understanding the consequences.
Future work
Actions and high-quality use cases
Currently, my assistant only has read-only actions, but I'm interested in letting it add items to my to-do list, help me break them down, describe them, code tasks, etc.
However, I will likely only add actions as a consequence of high-quality use cases. The next use cases I want to tackle are related to supporting me when studying or executing a personal project. In essence, the kind of work I do that generate posts for this blog represent the things I'd like to enjoy more when I work with my assistant. If it can't help in those cases, I'm unsure it is worth investing further.
I'm very inspired by Engelbart (1962) and thinking of my assistant as this Problem solving tool. Thus, it needs to bring clarity about the problem, have the same context I do about it, nudge me, bring the perspective of other specialists, support execution, create artifacts that facilitate the reuse by me and others, and more.
Referencing docs, people, workspaces, and projects
One thing I like about Dia is its ability to reference elements using @, such as a specific tab, favorite, or website visited within the last seven days. I'd love to expand it to docs, people, projects, and workspaces.
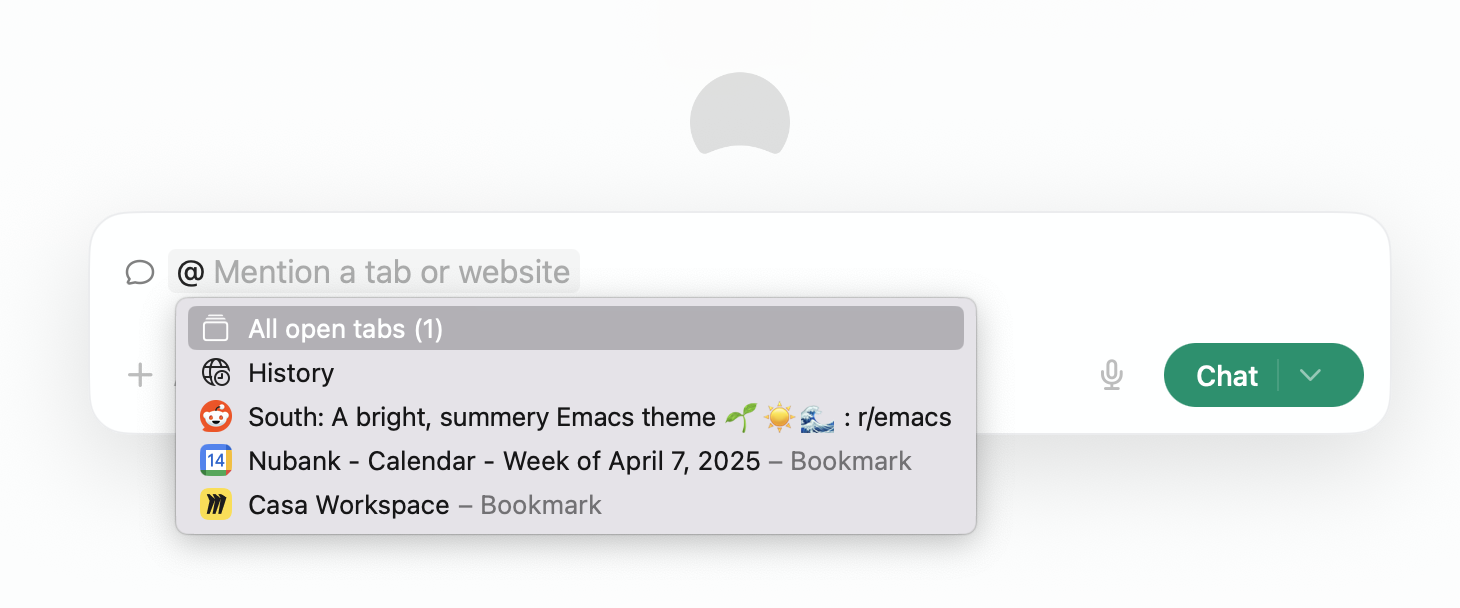
Further, the workspace and project aspects align better with my intention to work on specific use cases. I wonder if I can configure my assistant to recognize when we are working on a specific project or topic, similar to how a colleague would recall details from a project we've worked on together for a while.
Memory
Building on the previous item, I aim to make memory more structured by incorporating a simple semantic search function for historical conversations. I appreciate approaches like those in Gutiérrez et al. (2024), particularly how ChatGPT's memory experience has improved over the last couple of months. A basic thing I expect when working with data is that the system improves as I use it and generate more data.
