The collaboration-information problem
Cognition, time, and energy constrain our agency as individuals. We break it a bit via collaboration: combined cognition, time, and energy to achieve more in a group. Further, a group of groups. An organization. Constraints hit again. One can’t add people to a group and indefinitely benefit from it. There is a limit in human communication 1 that limits group productivity 2. It does not scale.

Communication is about information flow. Collaborative work towards a goal is about using that information to achieve it. Not all information generated needs to flow, and not all details of what needs to flow need to be informed. There are filtering and compression tasks.
When we execute these tasks, there is a performance issue: not all information and details that flow is needed to achieve the group goal. Not all information or details are necessary to accomplish the goal flow.
I suggest that succeeding on these tasks with high performance is needed to complexify what we can achieve in human organizations.
Evolution gives us the evidence. Our brain needs to make an effort to focus on what matters 3, to split relevant from irrelevant. Biological systems evolved using hierarchy to complexify from cells with a relatively low agency. The cells of our body are specialized. They don’t know everything going on to do the complex holistic work 4. We, humans, emerge from this hierarchy, which makes me think they do it well. Biological systems have a long history of evolution. Social systems, like a company, do not do as much.
I’m interested in the collaborative knowledge work that happens in companies at scale. Especially analytics, software, and product. I see a gap between knowledge creation and application. We fail to make knowledge relevant.
A Company as a social system collaborating towards a shared goal
If a company as a system was not short in collective cognition, I would not expect to systematically observe:
- Committing the same mistakes;
- Applying a certain approach while a better one is known and proven internally;
- Missing synergies;
- Reinventing the wheel;
It is not a documentation problem. Documenting is only the first step. It is a collective knowledge creation-application gap.
A company can register all their incidents in Post Morten notes. What do we expect from that document hidden in a digital drawer? Should we all go through it weekly, monthly, and yearly and refresh what we know about getting things wrong? How that representation of knowledge will interact with what is happening daily?
Though we document, we still depend on humans as information retrieval devices.
The burden of being an information-retrieval device as a human
Many questions are asked in a company in search of information instead of collaboration:
- Who worked on it?
- Where can I find it?
- How do I know it?
- Who’s responsible for it?
- Why did we do it?
People will bounce off ideas with higher tenure people to know about past failures, similar projects, who to talk to, and why people did things the way they did. To get a historical perspective. Then these people might retrieve a document to them with details.
We do it because high-tenure people have a mental index of the organization’s knowledge body, and they have a semantic search to point to what is relevant or not, including high levels of abstraction. E.g., you might not cite “behavioral change” as part of the project. Still, that person can read between the lines and match it to other initiatives involving behavioral change, even if they differ in their domains.
When people cannot answer it, they will feel someone else should and vaguely route it: “I think you should talk to Alice; she has been here since the beginning”. Evidently, no one will be able to carry the whole knowledge body of a company in their mind.
On the other side, after generating knowledge, we face many questions:
- Who is interested in it? Why?
- How and where should I broadcast it?
- How will I know if people who will need it in the future will find it?
We have relative success in applying it once, but we mostly fail to reuse it.
Knowledge is supposed to be modular
The information repositories we use, like Google Drive, have poor search capabilities. It retrieves what we mostly know to exist. Imagine we are a team starting a project to redesign a referral program. There is some “internal bibliographical review” to do.
- What are the nudges we did in the app, and how successful were they?
- Why the current referral program is the way it is?
- Have we tried to change it before?
The intended outcome is to have incremental customer releases via the referral program, which is quite specific. Nonetheless, numerous generic assumptions will support different solutions from our space.

They might not be as specific as we want to discard an idea. We might have previous interviews, surveys, or experiments showing minor customer sensitivity to monetary incentives, but we think the referral context can change it. However, it will undoubtedly impact the discovery design and the amount of evidence needed to accept it.
Applying collective knowledge implies spreading and reusing proven assumptions efficiently as building blocks.
In a large organization, one will hardly know which experimental results from the last week performed by the entire company are relevant to one’s context. Or which hypothesis we proved one could reuse for a new endeavor.
An example of the usage of knowledge modularity is research. In an article, we can see the references building up to enable shortcuts and efficiency via reusability. Of course, academia does it at a high cost.
As a more objective building block, we have code. Code is a sub-problem of what we are describing. It is intended to be reused. However, at least in analytics, reusability is lower than what I would expect. There are many pointed villains. Computational notebooks are commonly criticized for their low reproducibility and reusability 5.
Envisioning the system
This struggle is not new. Engelbart (1962) 6 proposed a framework for cognition augmentation based on Human and Tool systems. The pinnacle of his framework is the Concurrent development, Integration, and Application of Knowledge (CODIAK). Engelbert calls it groupware, a software for group work.
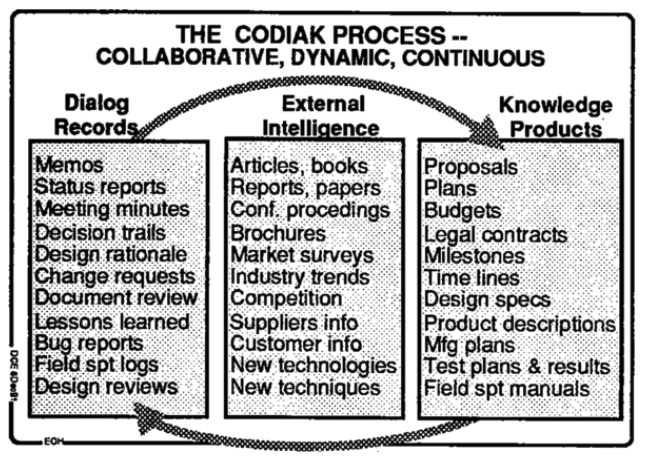
The CODIAK covers in spirit what we are talking about. Most of the attention goes into general challenges of Information Systems and collaborations, like integrating different media types, access control, and interfacing between other systems. We can say that current systems cover more or less the requirements for Engelbert’s CODIAK.
However, Engelbert predicts that radical changes in important parameters of this system can bring first a steep quantitative change, then a qualitative change that will bring surprising new ways of work 7. He believes it would come from tool systems since they can impose a radical change in speed, function, quality, etc.
Engelbert recognizes speech recognition as a possible transformative technology in this context 7. It would contribute to the flexibility of contributing and integrating knowledge. Nonetheless, I don’t think speech recognition delivered it in the collaborative knowledge-work context. It might be great to document knowledge. However, alone it does not boost its application, which could only increase the creation-application gap.
The chances are we will see Large Language Models (LLM, e.g., Generative Pre-training, GPT-3) generating this radical change. First, by transforming textual data into knowledge creation in a very flexible way (including what comes from speech recognition). Second, manipulating knowledge to increase its application in a way that is not qualitatively complex for humans but quantitative impossible: in thousands of people organizations. LLM will tighten the knowledge creation-application gap.
Still, I don’t see ChatGPT as a central savior system. The examples are mere illustrations. I believe in a series of specialized tools for knowledge workers who need to collaborate originated from applications of LLMs fine-tuned with expert knowledge. Further, the capability to point sources will be crucial to keep humans in the loop. It is a Knowledge Platform. We want to reduce the friction of applications to close the creation-application gap.
The fact academia needs to explicitly build on top of knowledge made an early signal of this kind of system for academic research in the form of Elicit, an AI Research Assistant, or even the Explain Paper.
A personal nano-experience
I’ve been using org-roam for a while. It applies the Zettelkasten method to Emacs. In summary, it is a note-taking system in which you link notes. The start is fascinating; you make many connections and remember every note. However, as you add more notes, it gets harder to connect or to remember you have a useful note when living a specific situation 8. The knowledge creation-application gap will start to increase. After 2.5y, I have 3.4k notes. It becomes non-trivial to connect and apply.
What is the point of taking personal notes if you can’t remember them?
First, on the “personal” aspect of the notes: It is similar to looking at the picture you took of the Eiffel Tower or getting a picture of it from Google Images. When you look at your own photo, you retrieve more than the image of the tower. You get back part of what happened before and after and how you felt. Your own madeleine moment 9. The same applies to knowledge. When I look at my notes, it refreshes an entire region in my brain and retrieves more than the specific things on that note, mainly because I will start exploring the neighbor nodes that exist because I’ve created them, which makes the process flow very well.
Now, the puzzle: how to make me look at a specific note at a convenient time?
A good search makes a lot of difference. I have indexed all my notes using open-source LLMs to close the creation-application gap. I can relax when creating a new note since I’m confident about finding it when it is convenient. When I write, I create a “thinking arena” in which I keep querying my notes, grab some, link to the thinking box, explore the notes graph, query more, and keep this process until I feel I could refresh my references on the subject accordingly.

Nonetheless, the collaborative knowledge-work setting is slightly different. You would look at the pictures of others. However, I see it as an intermediate point between looking at personal pictures and doing a Google Image search. It is more like traveling in a group where you are not always together, but you touch basis. You can explore different things, but you had breakfast together and shared your plans. You were in the same city, weather, and culture simultaneously.
In a company, there are common languages, rituals, and goals. One will see many familiar things to trigger their internal knowledge graph.
At this point, we get back to the original puzzle: how to make it likely for someone to apply the knowledge available in their organization at a low cost?
The revolutionary flexibility
The revolutionary aspect of it will come from the completeness of sources and broad coverage of the application. Generating data for this system won’t be an option. Everything a team codes, writes, or says, becomes unstructured data. This high flexibility of the input makes it revolutionary.
Code base (Github), document repository (Google Drive), work management (Jira), and meetings (Zoom). Unstructured data converts diverse knowledge packages into common ground.
Application is not easy or trivial, but the large surface for application will probably be quickly covered, motivated by the high return. The interface and the output have interesting characteristics: conversational, accessible, and structure-free.
The common goal for these applications is to entitle the system to make the application happen. E.g., given someone is writing code, it can’t let them not use what we know or have.
What if LLM are just fancy parrots?
It doesn’t matter. The fact we are increasing data ingestion and quality of information retrieval by orders of magnitude are likely enough. Cost reduction is likely more important at this point than improving its skills. In the end, it is augmenting collective intelligence and not replacing it. It doesn’t need to have any or all the traits of what we’d call intelligence 10 11. We are not envisioning a central intelligent entity telling an organization what to do. It is closer to what computers and networks of information systems did.
Sub-systems and applications
The DRY becomes DRO
There is a principle in Software Engineering called DRY: Don’t Repeat Yourself 12, which states we should avoid repetition via good abstractions. The frustration is better expressed by the opposite, WET: write everything twice, write every time, we enjoy typing, or waste everyone’s time.
Suppose you extend it to everything else in an organization. In that case, it means solving the same puzzle twice, running the same experiments every time, enjoying creating remarkably similar tools, reinventing the wheel, in summary, wasting energy.
Nonetheless, we should assume we don’t do it because we like it but because we have a narrow context. It is way trickier for an individual or group to realize it because they might be doing something inspiring and novel for them, but unaware they are repeating someone else in the organization, which is organizationally unexciting.
The system will have access to the knowledge base and have the objective of not letting someone waste energy. We can imagine many sub-systems.
For coding, it can iteratively read what someone is writing and pop up to tell them when it is confident enough that the organization has an excellent abstraction to deal with that. Even if it requires the person writing the complete code, realizing it and replacing it is beneficial in the long term.

When writing a Request For Comments (RFC) or Product Requirement Document (PRD), someone should get instant tips on what the team knows about that subject and decide how to incorporate it. Especially in an RFC. You automatically request comments from the whole organization’s knowledge body as you write down an issue, the assumptions involved, the solution, the alternative solutions, etc. We write to think, but we will start to write to think collectively. That’s the augmentation. Evidently, it is supportive. It brings to light likely relevant pieces of knowledge, but it will require the team to go deeper into the references. It is a collective intelligence collection.
The “don’t repeat yourself” becomes “don’t repeat ourselves”.
Rationale retrieval
Most of the time, we think a decision doesn’t make sense. It makes but given a context. However, retrieving the context hugely depends on people or a tortuous investigation of the many artifacts. Is it explained in a Pull Request, Slack thread, slide presentation, or RFC? It does not matter. Design decisions can be documented somewhere, but it is mighty to retrieve them so easily.

Creative collaboration
- Your problem looks like a lot with what happened on the Pricing team two years ago. Did you take a look at it?
- I think we can use this internal tool to solve it. If I’m not mistaken, it fits your use case.
This kind of observation wouldn’t be as valuable anymore. The information-retrieval part of collective work should be automatic and though not perfect, better than what anyone in the organization can do and what most reasonable sizeable groups could do. Managers lose their role of knowledge and networking hubs and replace by doing more understanding, thinking, and rethinking the collected information.
The example provided is quite simplistic. But we can imagine a few background prompts running along with a project proposal for knowledge collection:
- From all the internal tools, which are the most likely useful to execute this project?
- From all the experiments in our base, which are the most related to the proposal?
- Whom in the company has worked on similar initiatives?
- Whom in the company is currently working on similar projects?
- What were the common mistakes we made in the past on related topics?
A room full of people is for interpreting knowledge, mixing it, challenging current knowledge, designing new experiments, and clarifying hidden assumptions. Processing a large batch of information, abstraction, and correlation becomes a machine task. In this context, abstraction transforms text into vectors with interesting dimensions to correlate information.
Proactive Internal Recommender System
It is appealing that someone could query for internal knowledge when doing a new project. Having relevant information brought to us at the opportune moment is even more enjoyable.
The system knows what I’m working on, what I have worked on in the past, and my team’s current and possible challenges. It is watching every meeting, reading every document, and checking every project to proactively tell me what is relevant.
When you are creating a description of a project or task in a work management tool, the system can proactively go through it and answer: given the knowledge corpus, tools, and current projects of this company, what is relevant to show to this person?
Organic communication paths will enable organizations to do better
Conway’s law states that system design reflects the communication structure of an organization 13, which applies to software systems. Conway’s law concerns communication cost and not org structure 2. Communication costs will reduce drastically with the support of groupware systems based on LLM. They will non-stop correlate information generated in all the parts of a company. It will take part of the burden of being so cognitively limited when designing software systems.
Organizational recommendation
Let’s take as a principle for an organizational chart to establish the most relevant communication channels to achieve an organization’s goal. We can flip from “put those teams together because they should communicate” to “these teams are communicating lately, put them together to optimize it”. Suppose we have a system that distributes relevant information, data from where the information is generated, and who is consuming it. In that case, it can support us in a data-driven organizational chart.

A dynamic hierarchy
We can go further. It could make organizational charts irrelevant. Hierarchy exists to limit information flow, which enables systems to become more complex 4. Not all the information needs to flow to all parts to collectively achieve complex goals. What if the parts get proactive support and tools to shape the communication flow? More complex collective behavior can emerge from parts getting relevant information based on a dynamic system that observes what they did, what they are doing, and their sub-goals, and the same for every other part of the organization. Communication paths shape what organizations can do.
Knowledge governance and attribution
Every domain and team will have reasons to document their knowledge in a convenient way to be processed and attributed. You want to expose everything your team learns from experiments, fails, analyses, etc. Just as a team wants to expose capabilities and data internally via APIs.



The incentive will be attribution. It enables rewarding helpful knowledge for the organization. If a team fails in a learningful way, it will generate a lot of knowledge that will be reused by many people in the organization, which will trace back to the failure and show how significant that contribution was.

Self-organization for technological advancement
Self-organization happens when a system can add, change, or evolve its structure. It happens via simple rules and elements: a raw material to select, a process that adds variety, and a selection step that interacts with what the system cares about and can signal success 4.
When we see a company as a system, its tech advance happens on top of a knowledge base (internal and external). The envisioned systems make it highly accessible. If the human creativity to insert variety into it and the capacity to experiment don’t become a bottleneck, we can expect a higher rate of tech advancement.
Accessibility means having available the stepping stones collected from a large group. We can hypothesize that tuning a system to offer surprising stepping stones to one’s endeavor can lead to great innovative results 14 15.
Conclusion
Human systems will be important in this process. Using language to represent knowledge and making knowledge flow via Language Models will require people to pay more attention to language and communication. Surely, less structured than what Engelbert predicted 7, but it will become a matter of data quality. Regarding LLMs, current evidence points to a lot of assistance and expert knowledge 16, but it doesn’t seem to be a barrier. A system that inherits language processing from LLM gets polished by expert software engineers on sub-tasks research in software engineering considers important and fine-tuned on an internal code base look like the kind of product we will consume.
References
-
Brooks Jr, F. P. (1995). The mythical man-month: essays on software engineering. Pearson Education. ↩
-
The Only Unbreakable Law (2022), Youtube video. ↩ ↩2
-
Rensink, R. A. (2000). The dynamic representation of scenes. Visual cognition, 7(1-3), 17–42. ↩
-
Meadows, D. H. (2008). Thinking in systems: a primer. Chelsea green publishing. ↩ ↩2 ↩3
-
Chattopadhyay, S., Prasad, I., Henley, A. Z., Sarma, A., & Barik, T. (2020). What’s wrong with computational notebooks? pain points, needs, and design opportunities. In , Proceedings of the 2020 CHI conference on human factors in computing systems (pp. 1–12). ↩
-
Engelbart, D. C. (1962). Augmenting human intellect: a conceptual framework. Menlo Park, CA, 21. ↩
-
Engelbart, D. C. (1992). Toward high-performance organizations: a strategic role for groupware. In Proceedings of the GroupWare (pp. 3–5). ↩ ↩2 ↩3
-
Proust, M. (1913). A la recherche du temps perdu: du côté de chez Swann. ↩
-
Wong, Matteo. (2023) The Difference Between Speaking and Thinking. Link - there is a pay wall, but the first two paragraphs are enough. ↩
-
LeCun, Y. Browning, J. (2022) AI And The Limits Of Language. Link. ↩
-
Thomas, D., & Hunt, A. (2019). The pragmatic programmer. ↩
-
Conway, M. E. (1968). How do committees invent. Datamation, 14(4), 28–31. ↩
-
Stanley, K. O., & Lehman, J. (2015). Why greatness cannot be planned: the myth of the objective. ↩
-
Burkus, D. (2013). The myths of creativity: the truth about how innovative companies and people generate great ideas. John Wiley & Sons. ↩
-
Fu, Y. P., & Khot, T. (2022). How does gpt obtain its ability? tracing emergent abilities of language models to their sources. Yao Fu’s Notion. ↩
