Learn an SOP-structured prompt from an agent with deterministic behavior
Table of Contents
- 1. Abstract
- 2. Introduction
- 3. Related Work
- 4. Problem Setup
- 5. Methodology
- 6. Experimental Setup
- 7. Learnings
- 8. Results
- 9. Conclusion
- 10. Open Questions
- 11. Future Work
- 11.1. 1. Generate synthetic data for three very distinct use cases where the policy to solve them is more complex, and ontroduce use-cases where an action with a side effect on user data is needed
- 11.2. 2. Explore prototype discovery or clustering to generalize beyond known topics.
- 11.3. 3. Add dynamic regression tests that lock in the final prompt and guard against regressions.
- 11.4. 4. Add other success metrics beyond cosine similarity.
- 12. References
An evolution of Mimicking a binary deterministic agent.
1. Abstract
I investigate whether a structured prompt plus LLM-based coaching can fully imitate a deterministic binary policy without exposing its rule. I generate 200 GPT-3.5 sentences evenly split between coffee and sports topics, label them, and use a topic-aware “tiny agent” to emit one of two canned replies (“I see you are a person of taste!” vs. “Well, I don’t like sports.”). A DSPy mimic agent with a three- block prompt (general guidance + two SOP placeholders) is trained in 12 epochs using cosine similarity over OpenAI embeddings, evaluator histories, and LLM-authored case reports. Having as a starting point the algorithm in Mimicking a binary deterministic agent, I introduced many mechanisms in the learning loop to ensure the coverage of all the cases, like clustering the input to identify every sub-case the AI agent should address, bringing worst performing cases up, and making target edits with ADD/EDIT/DEL options to preserve parts of the prompt untouched. Further, I use now an early stopping argument to stop the learning process earlier if there isn't progress. The agent could achieve a test score of ~1, becoming indistinguishable from the agent that generated the data.
2. Introduction
I want to set the task of crafting an AI Agent as a learning from data task based on mimicking a target behavior. This setting ease all use cases where copying an existing behavior has advantages.
I will create a "tiny agent", in a sense it will have two behaviors, and try to learn these behaviors as the prompt of an LLM we train to imitate the tiny agent.
3. Related Work
This work is inspired by optimization frameworks like GEPA (Lakshya A Agrawal AND Shangyin Tan AND Dilara Soylu AND Noah Ziems AND Rishi Khare AND Krista Opsahl-Ong AND Arnav Singhvi AND Herumb Shandilya AND Michael J Ryan AND Meng Jiang AND Christopher Potts AND Koushik Sen AND Alexandros G. Dimakis AND Ion Stoica AND Dan Klein AND Matei Zaharia AND Omar Khattab, 2025) and Agentic Context Engineering (Zhang, Qizheng and Hu, Changran and Upasani, Shubhangi and Ma, Boyuan and Hong, Fenglu and Kamanuru, Vamsidhar and Rainton, Jay and Wu, Chen and Ji, Mengmeng and Li, Hanchen and Thakker, Urmish and Zou, James and Olukotun, Kunle, 2025).
The key difference from these works is about the signal that guides the optimization. Both of them rightly uses a success metric based on the task of interest: does the code written by the agent executes or produces the expected output? how the output scores regarding import criteria for the task at hand, likle correctness, conciseness, or politeness?
However, these are expensive signals to obtain. One need to understand very well a task, create specific evaluators, or have great annotated data.
The take here is to simplify it as mimicking the output of a target agent at the expense of not focusing on the outcome of the agent on the task. In this scenario, the target agent becomes an upper bound of performance on the task. At the same time, identifying if an AI agent is able to behave just as another agent (a human, or a system), is a generic task that is easy to set.
4. Problem Setup
There is an Agent, in a the broader sense as defined in Sutton, Richard S. And Barto, Andrew G. (2018):
I want to learn this agent behavior by only observing their observations and actions.
I succeed if I can build another agent that when seen behaving under the same environment is indistinguishable from the original agent it learned from.
5. Methodology
I use a target & learning agent framework.
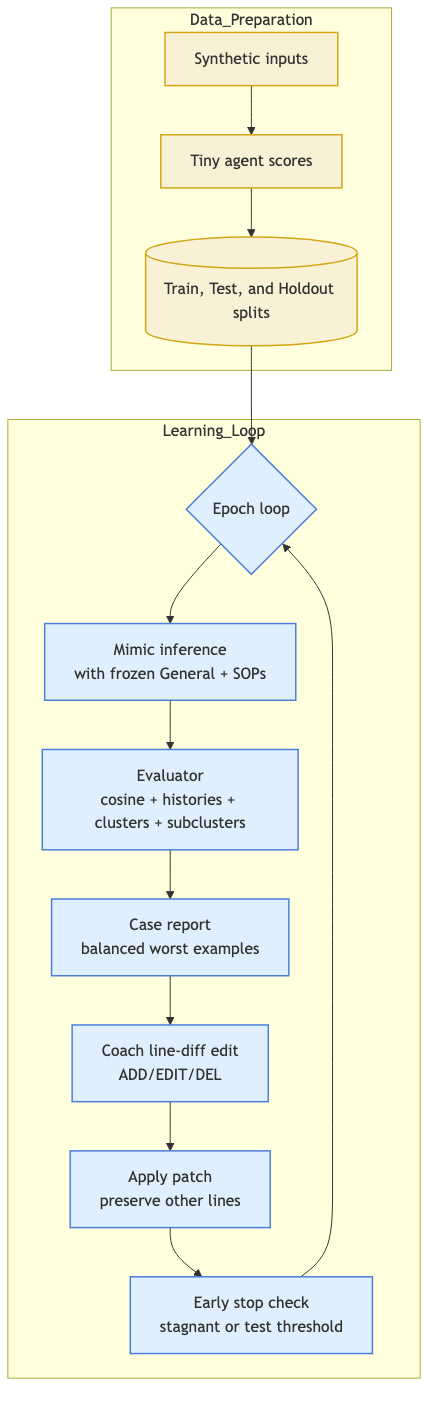
In this specific experiment, we imitate a deterministic two-response policy via prompt engineering plus LLM-based coaching with line-level edits. The current procedure:
- Synthetic data – GPT-3.5-turbo generates 200 first-person sentences (coffee + sports). Only text and tiny-agent outputs are exposed downstream; topic labels are not given to the coach.
- Structured mimic prompt – One frozen `[General guidance]` block holds routing; SOP blocks (currently one) contain the policy. General is frozen by default; SOP text must be atomic pseudo-code (one condition/action per line).
- Evaluator & clustering – Batched mimic inference; evaluator logs cosine similarity, histories, and builds K-means clusters sized to the SOP count, with sub-clusters inside each cluster. SOP similarity matrices are computed for diagnostics.
- Case reporting – Per-epoch anchor + nearest neighbors for a case report; worst examples per cluster/subcluster are surfaced to the coach.
- Coach update (line-diff) – Coach receives cluster report, balanced worst examples, prompt blocks, and change log; returns line-level directives (ADD/EDIT/DEL) for the sampled SOP. Patches are applied preserving untouched lines. Early stopping can trigger on stagnant epochs or a test-metric threshold.
Assumptions: topics are balanced; mimic never sees explicit policy rules; cosine similarity uses OpenAI embeddings (text-embedding-3-small); edits are line-local to stabilize prompts.
6. Experimental Setup
6.1. Configuration
%load_ext autoreload %autoreload 2
6.2. Creating the input text
I use GPT-3.5 to generate 200 examples. In 100 examples, we will talk about coffee. In the other 100, we will talk about sports.
from __future__ import annotations import json import time from pathlib import Path from typing import Dict, List import openai DATA_PATH = Path("experiments/mimic_tiny_agent/coffee_vs_sports.jsonl") client = openai.OpenAI() def _request_sentence(topic: str, model: str) -> str: """Ask GPT-3.5 for a sentence about the desired topic.""" if topic == "coffee": user_prompt = ( "Write one short first-person sentence (<=25 words) describing why I love coffee or a memorable coffee moment." ) elif topic == "sports": user_prompt = ( "Write one short first-person sentence (<=25 words) describing my favorite sport or why I enjoy it." ) else: raise ValueError(f"Unsupported topic: {topic}") response = client.chat.completions.create( model=model, temperature=0.8, max_tokens=80, messages=[ { "role": "system", "content": "You craft concise, vivid personal statements that follow the user instructions exactly.", }, {"role": "user", "content": user_prompt}, ], ) return response.choices[0].message.content.strip() def generate_dataset_with_gpt( n_examples: int = 200, *, model: str = "gpt-3.5-turbo", save_path: Path = DATA_PATH, ) -> List[Dict[str, object]]: """Call GPT-3.5 to synthesize coffee and sports statements and persist them.""" if n_examples % 2 != 0: raise ValueError("n_examples must be even so it can be split evenly") save_path.parent.mkdir(parents=True, exist_ok=True) half = n_examples // 2 dataset: List[Dict[str, object]] = [] for idx in range(n_examples): topic = "coffee" if idx < half else "sports" text = _request_sentence(topic, model) dataset.append( { "text": text, "topic": topic, "model": model, "timestamp": time.time(), } ) time.sleep(0.2) with save_path.open("w", encoding="utf-8") as fh: for row in dataset: fh.write(json.dumps(row) + "\n") return dataset def load_or_create_dataset(path: Path = DATA_PATH) -> List[Dict[str, object]]: if path.exists(): print(f"Loading cached dataset from {path}") return [json.loads(line) for line in path.read_text().splitlines() if line] print("Dataset not found on disk; generating via GPT-3.5...") return generate_dataset_with_gpt(save_path=path) synthetic_examples = load_or_create_dataset() coffee_count = sum(1 for item in synthetic_examples if item.get("topic") == "coffee") sports_count = sum(1 for item in synthetic_examples if item.get("topic") == "sports") print( f"Loaded {len(synthetic_examples)} examples; " f"coffee={coffee_count} | sports={sports_count}." )
Loading cached dataset from experiments/mimic_tiny_agent/coffee_vs_sports.jsonl Loaded 200 examples; coffee=100 | sports=100.
6.3. Creating the tiny agent
We create a function that's able to generate an answer following:
- Whenever the topic is "coffee", it should answer: "I see you are a person of taste! I like coffee, too.";
- Whenever the topic is "sports", it must say: "Well, I don't like sports.".
from typing import Iterable COFFEE_RESPONSE = "I see you are a person of taste! I like coffee, too." SPORTS_RESPONSE = "Well, I don't like sports." DEFAULT_RESPONSE = SPORTS_RESPONSE def tiny_agent_response(user_text: str, *, topic: str | None = None) -> str: label = (topic or "").strip().lower() if label == "coffee": return COFFEE_RESPONSE if label == "sports": return SPORTS_RESPONSE if "coffee" in user_text.lower(): return COFFEE_RESPONSE return DEFAULT_RESPONSE def batch_tiny_agent_response( inputs: Iterable[tuple[str, str | None]], ) -> list[str]: return [tiny_agent_response(text, topic=topic) for text, topic in inputs] print(tiny_agent_response("I brewed a silky pour-over", topic="coffee")) print(tiny_agent_response("Practicing my backhand", topic="sports"))
I see you are a person of taste! I like coffee, too. Well, I don't like sports.
6.3.1. Scoring all the input text using the tiny agent
from collections.abc import Sequence from pprint import pprint def score_dataset_with_tiny_agent( dataset: Sequence[dict[str, object]], ) -> list[dict[str, object]]: """Append the tiny agent answer to every input example.""" scored: list[dict[str, object]] = [] for row in dataset: topic = row.get("topic") answer = tiny_agent_response(str(row["text"]), topic=topic) scored.append({**row, "tiny_agent_output": answer}) return scored scored_examples = score_dataset_with_tiny_agent(synthetic_examples) print(f"Scored {len(scored_examples)} examples with the deterministic agent.") pprint(scored_examples[:3])
Scored 200 examples with the deterministic agent.
[{'model': 'gpt-3.5-turbo',
'text': 'The first sip of my morning espresso awakens my senses and sets a '
'positive tone for the day ahead.',
'timestamp': 1763237270.6815271,
'tiny_agent_output': 'I see you are a person of taste! I like coffee, too.',
'topic': 'coffee'},
{'model': 'gpt-3.5-turbo',
'text': "I love coffee because it's a warm hug in a cup that jumpstarts my "
'day with its rich aroma.',
'timestamp': 1763237271.866124,
'tiny_agent_output': 'I see you are a person of taste! I like coffee, too.',
'topic': 'coffee'},
{'model': 'gpt-3.5-turbo',
'text': 'The first sip of rich, aromatic coffee transports me to cozy '
'mornings and fuels my passion for creativity and productivity.',
'timestamp': 1763237273.029643,
'tiny_agent_output': 'I see you are a person of taste! I like coffee, too.',
'topic': 'coffee'}]
6.4. The mimic agent
We use DSPy to create a program that just has a generic prompt.
import os from typing import Any import dspy def ensure_dspy_configured() -> object: """Lazy-load the LM client used by DSPy.""" if dspy.settings.lm is not None: return dspy.settings.lm api_key = os.getenv("OPENAI_API_KEY") if not api_key: raise EnvironmentError( "OPENAI_API_KEY is not set. Export it before running DSPy cells." ) model_name = os.getenv("DSPY_LM_MODEL", "openai/gpt-4.1-mini") temperature = float(os.getenv("DSPY_LM_TEMPERATURE", "0.3")) max_tokens = int(os.getenv("DSPY_LM_MAX_TOKENS", "2048")) lm = dspy.LM( model_name, api_key=api_key, temperature=temperature, max_tokens=max_tokens, ) dspy.configure(lm=lm) return lm ensure_dspy_configured() class CommentOnClaim(dspy.Signature): user_claim = dspy.InputField(desc="The short statement provided by the user.") comment = dspy.OutputField( desc="A concise acknowledgement or observation about the claim." ) mimic_agent_structured_default = { "general_guidance": ( "Follow the SOP blocks below. Select the SOP whose examples best match the current input and apply only that block. Keep replies brief." ), "sops": [ "This is a placeholder standard operating procedure.", "This is a placeholder standard operating procedure.", ], } class PromptStructure: def __init__(self, general_guidance: str, sops: list[str]) -> None: self.general_guidance = general_guidance.strip() self.sops = [sop.strip() for sop in sops] def render(self) -> str: lines = ["[General guidance]", self.general_guidance] for idx, sop in enumerate(self.sops, start=1): lines.append(f"[sop-{idx}]") lines.append(self.sops[idx - 1]) return "\n".join(lines) def block_names(self) -> list[str]: return ["general"] + [f"sop-{idx}" for idx in range(1, len(self.sops) + 1)] def get_block_text(self, block_name: str) -> str: if block_name == "general": return self.general_guidance if block_name.startswith("sop-"): idx = int(block_name.split("-", 1)[1]) - 1 return self.sops[idx] raise KeyError(f"Unknown block {block_name}") def update_block(self, block_name: str, new_text: str) -> None: cleaned = new_text.strip() if not cleaned: return if block_name == "general": self.general_guidance = cleaned return if block_name.startswith("sop-"): idx = int(block_name.split("-", 1)[1]) - 1 if 0 <= idx < len(self.sops): self.sops[idx] = cleaned return raise KeyError(f"Unknown block {block_name}") class MimicAgent(dspy.Module): """DSPy program with a structured prompt (general guidance + SOP blocks).""" def __init__( self, *, general_guidance: str | None = None, sop_texts: list[str] | None = None, sop_count: int = 2, ) -> None: super().__init__() template = mimic_agent_structured_default base_general = general_guidance or template["general_guidance"] base_sops = sop_texts or template["sops"] if sop_count > len(base_sops): base_sops = base_sops + [base_sops[-1]] * (sop_count - len(base_sops)) else: base_sops = base_sops[:sop_count] self.prompt_state = PromptStructure(base_general, base_sops) self.generator = dspy.Predict(CommentOnClaim) @property def base_prompt(self) -> str: return self.prompt_state.render() def forward(self, user_claim: str) -> dict[str, Any]: # type: ignore[override] instructions = ( f"Instruction:\n{self.base_prompt}\n" f"User claim: {user_claim.strip()}\n" "Comment:" ) prediction = self.generator(user_claim=instructions) return { "prompt": self.base_prompt, "mimic_output": prediction.comment, } def get_prompt_blocks(self) -> dict[str, str]: return {name: self.prompt_state.get_block_text(name) for name in self.prompt_state.block_names()} def update_block(self, block_name: str, new_text: str) -> None: self.prompt_state.update_block(block_name, new_text) mimic_agent = MimicAgent(sop_count=1) demo_reply = mimic_agent("I'm experimenting with new pour-over routines") demo_reply
| prompt | : | [General guidance]\nFollow the SOP blocks below. Select the SOP whose examples best match the current input and apply only that block. Keep replies brief.\n[sop-1]\nThis is a placeholder standard operating procedure. | mimicoutput | : | Exploring new pour-over routines sounds like a great way to refine your brewing skills and discover unique flavors. |
6.5. The learning algorithm
6.5.1. The evaluator
The evaluator input: the user input, the tiny agent output, and the mimic agent output.
The evaluator output: a similarity metric calculated comparing the tiny agent output to the mimic agent output; a list of the last n outputs from the mimic agent on that same input, and a list of the last k training examples and mimic outputs and their scores.
from __future__ import annotations import math import time from collections import Counter, defaultdict, deque from dataclasses import dataclass from typing import Any, Deque, Dict, Literal import numpy as np import openai SimilarityMetric = Literal["bleu", "embedding_cosine"] def _tokenize(text: str) -> list[str]: return [token for token in text.lower().split() if token] def _ngram_counts(tokens: list[str], n: int) -> Counter[tuple[str, ...]]: if len(tokens) < n: return Counter() return Counter(tuple(tokens[i : i + n]) for i in range(len(tokens) - n + 1)) def compute_bleu(reference: str, hypothesis: str) -> float: ref_tokens = _tokenize(reference) hyp_tokens = _tokenize(hypothesis) if not hyp_tokens: return 0.0 weights = [0.25, 0.25, 0.25, 0.25] precisions = [] for n in range(1, 5): ref_counts = _ngram_counts(ref_tokens, n) hyp_counts = _ngram_counts(hyp_tokens, n) overlap = sum( min(count, ref_counts[gram]) for gram, count in hyp_counts.items() ) total = sum(hyp_counts.values()) or 1 precisions.append(overlap / total if overlap else 1e-9) log_precision = sum(w * math.log(p) for w, p in zip(weights, precisions)) brevity_penalty = 1.0 ref_len = len(ref_tokens) hyp_len = len(hyp_tokens) if hyp_len <= ref_len and hyp_len > 0: brevity_penalty = math.exp(1 - ref_len / hyp_len) return float(brevity_penalty * math.exp(log_precision)) def cosine_similarity(vec_a: np.ndarray, vec_b: np.ndarray) -> float: denom = np.linalg.norm(vec_a) * np.linalg.norm(vec_b) if denom == 0: return 0.0 return float(np.dot(vec_a, vec_b) / denom) @dataclass class EvaluationRecord: user_input: str tiny_output: str mimic_output: str similarity: float metric: SimilarityMetric timestamp: float class TinyAgentEvaluator: """Track similarity and histories for the mimic vs. tiny agent comparison.""" def __init__( self, *, metric: SimilarityMetric = "bleu", per_input_history: int = 5, training_history: int = 50, embedding_model: str = "text-embedding-3-small", ) -> None: self.metric = metric self.per_input_history = per_input_history self.training_history = training_history self.embedding_model = embedding_model self._per_input_records: dict[str, Deque[EvaluationRecord]] = defaultdict( lambda: deque(maxlen=per_input_history) ) self._global_records: Deque[EvaluationRecord] = deque(maxlen=training_history) self._embedding_cache: dict[str, np.ndarray] = {} self._embedding_client = openai.OpenAI() # -- metrics ----------------------------------------------------------------- def _bleu_similarity(self, tiny_output: str, mimic_output: str) -> float: return compute_bleu(tiny_output, mimic_output) def _embedding_similarity(self, tiny_output: str, mimic_output: str) -> float: tiny_vec = self._embed_text(tiny_output) mimic_vec = self._embed_text(mimic_output) return cosine_similarity(tiny_vec, mimic_vec) def _embed_text(self, text: str) -> np.ndarray: cache_key = text.strip() if cache_key in self._embedding_cache: return self._embedding_cache[cache_key] if not cache_key: vec = np.zeros(1536, dtype=np.float32) self._embedding_cache[cache_key] = vec return vec response = self._embedding_client.embeddings.create( model=self.embedding_model, input=cache_key, ) vec = np.array(response.data[0].embedding, dtype=np.float32) self._embedding_cache[cache_key] = vec return vec def _compute_similarity(self, tiny_output: str, mimic_output: str) -> float: if self.metric == "embedding_cosine": return self._embedding_similarity(tiny_output, mimic_output) return self._bleu_similarity(tiny_output, mimic_output) def similarity(self, tiny_output: str, mimic_output: str) -> float: """Public helper to compute similarity without mutating evaluator state.""" return self._compute_similarity(tiny_output, mimic_output) def embed_text(self, text: str) -> np.ndarray: """Expose embedding helper for downstream analysis.""" return self._embed_text(text) # -- public api --------------------------------------------------------------- def evaluate( self, *, user_input: str, tiny_output: str, mimic_output: str, ) -> Dict[str, Any]: similarity = self._compute_similarity(tiny_output, mimic_output) record = EvaluationRecord( user_input=user_input, tiny_output=tiny_output, mimic_output=mimic_output, similarity=similarity, metric=self.metric, timestamp=time.time(), ) per_input_buffer = self._per_input_records[user_input] per_input_buffer.append(record) self._global_records.append(record) return { "similarity": similarity, "metric": self.metric, "last_outputs_for_input": [ { "mimic_output": item.mimic_output, "tiny_output": item.tiny_output, "similarity": item.similarity, "timestamp": item.timestamp, } for item in list(per_input_buffer) ], "recent_training_examples": [ { "user_input": item.user_input, "mimic_output": item.mimic_output, "tiny_output": item.tiny_output, "similarity": item.similarity, "metric": item.metric, "timestamp": item.timestamp, } for item in list(self._global_records) ], } def describe_block_change(block_name: str, old_text: str, new_text: str) -> str: if old_text.strip() == new_text.strip(): return f"Block {block_name} unchanged." desc: list[str] = [f"Block {block_name}: "] if len(new_text) > len(old_text) * 1.1: desc.append("expanded details.") elif len(new_text) < len(old_text) * 0.9: desc.append("more concise wording.") old_words = set(old_text.lower().split()) new_words = set(new_text.lower().split()) added = list(new_words - old_words) removed = list(old_words - new_words) if added: desc.append( " Added cues: " + ", ".join(sorted(added[:5])) + ("..." if len(added) > 5 else "") ) if removed: desc.append( " Removed cues: " + ", ".join(sorted(removed[:5])) + ("..." if len(removed) > 5 else "") ) if len(desc) == 1: desc.append(" Rephrased while preserving intent.") return "".join(desc) def prompt_unified_diff(old_prompt: str, new_prompt: str) -> str: diff = difflib.unified_diff( old_prompt.splitlines(), new_prompt.splitlines(), fromfile="previous_prompt", tofile="updated_prompt", lineterm="", ) diff_text = "\n".join(diff) return diff_text or "(no textual diff)" def format_change_log(entries: list[dict[str, object]], limit: int = 3) -> str: if not entries: return "No prior prompt changes recorded." lines: list[str] = ["Recent prompt changes:"] for idx, entry in enumerate(entries[-limit:], start=1): delta = entry.get("delta") if isinstance(delta, float): delta_text = f"{delta:+.3f}" else: delta_text = "N/A" lines.append( f"[{idx}] block={entry.get('block_name')} Δmetric={delta_text} " f"prev={entry.get('prev_metric')} new={entry.get('new_metric')}" ) lines.append(f"Intent: {entry.get('intention')}") old_block = entry.get("old_block_text", "") new_block = entry.get("new_block_text", "") lines.append(f"Old block: {old_block}") lines.append(f"New block: {new_block}") diff_text = entry.get("diff", "") or "(no diff)" if isinstance(diff_text, str): snippet = diff_text if len(diff_text) <= 800 else diff_text[:800] + "\n..." lines.append("Diff:\n" + snippet) # Diagnostics about general block scope and overlap with SOPs (best-effort) try: latest_prompt = entries[-1].get("new_prompt", "") sections = latest_prompt.split("[") blocks: dict[str, str] = {} for section in sections: if section.startswith("General guidance]"): blocks["general"] = section.split("]", 1)[1].strip() elif section.startswith("sop-"): name, rest = section.split("]", 1) blocks[name] = rest.strip() general_text = blocks.get("general", "") lines.append("\nGeneral block diagnostics:") lines.append(f"- general_len_chars: {len(general_text)}") sop_names = [k for k in blocks.keys() if k != "general"] if sop_names: general_vec = evaluator.embed_text(general_text) for name in sop_names: sop_vec = evaluator.embed_text(blocks.get(name, "")) sim = cosine_similarity(general_vec, sop_vec) lines.append(f"- cosine(general, {name}) = {sim:.3f}") else: lines.append("- cosine(general, sop-#): n/a (no SOP blocks found)") except Exception: lines.append("\nGeneral block diagnostics: unavailable (parsing error)") return "\n".join(lines) def serialize_prompt_blocks(blocks: dict[str, str]) -> str: parts = [] for name, text in blocks.items(): parts.append(f"[{name}]\n{text}") return "\n\n".join(parts) evaluator = TinyAgentEvaluator( metric="embedding_cosine", per_input_history=3, training_history=10, ) sample_input = synthetic_examples[0]["text"] tiny_answer = tiny_agent_response(sample_input) mimic_answer = mimic_agent(sample_input)["mimic_output"] evaluator.evaluate( user_input=sample_input, tiny_output=tiny_answer, mimic_output=mimic_answer, )
| similarity | : | 0.02492614835500717 | metric | : | embeddingcosine | lastoutputsforinput | : | ((mimicoutput : Your description captures the invigorating effect of espresso well, highlighting how it can positively influence your morning mood. tinyoutput : Well, I don't like sports. similarity : 0.02492614835500717 timestamp : 1764090815.578356)) | recenttrainingexamples | : | ((userinput : The first sip of my morning espresso awakens my senses and sets a positive tone for the day ahead. mimicoutput : Your description captures the invigorating effect of espresso well, highlighting how it can positively influence your morning mood. tinyoutput : Well, I don't like sports. similarity : 0.02492614835500717 metric : embeddingcosine timestamp : 1764090815.578356)) |
6.5.2. The coach agent
The coach agent input: the evaluator output, and the current mimic agent's prompt. The coach agent output: a new prompt for the mimic agent.
class CoachSignature(dspy.Signature): evaluator_report = dspy.InputField( desc="Structured summary describing recent evaluator scores and samples." ) prompt_blocks = dspy.InputField(desc="Structured prompt broken into named blocks.") block_options = dspy.InputField(desc="List of valid block names to edit.") guidelines = dspy.InputField( desc="Non-negotiable constraints for how the revised prompt should be phrased." ) prompt_change_log = dspy.InputField( desc="Table describing prior prompt edits, diffs, and their metric deltas." ) case_examples = dspy.InputField( desc="Sample inputs with target/mimic outputs for focused comparison." ) case_reasoning = dspy.InputField( desc="Reasoned analysis describing why mimic outputs differ from targets." ) target_block = dspy.OutputField(desc="Name of the block to edit (e.g., general, sop-1).") updated_block_text = dspy.OutputField(desc="Rewritten text for the chosen block only, or line-level patch directives.") coach_rationale = dspy.OutputField(desc="Short explanation for the proposed change.") COACH_PROMPT_GUIDELINES = ( "Produce a standalone instruction for an agent to immitate a 'target agent'. " "Focus on what the agent should say to become indistinguishable from the target agent." "The target agent is following a policy and you must decode it by looking to its behavior and craft a prompt to the mimic agent to apply that same policy." "Be as precise as possible describing the process the target agent is following to insert in the mimic agent prompt." "Don't mention 'mimic agent' or 'target agent' in the prompt of the 'mimic agent' since it is unaware of them. " "You want to maximize the similarity between the target agent output and the mimic agent output by editing the mimic agent's prompt." "Respect the structured prompt: edit exactly one named block (general or sop-#) per iteration and leave all other blocks untouched." "Keep the [General guidance] block high-level (meta guidance only) and free of policy details; place behavioral rules in SOP blocks." "When writing a SOP, express the full branching policy as pseudo-code with atomic lines: one condition/action per line (condition -> action -> optional terminate). Use explicit if/else/then, ask/check/show verbs, and 'terminate' where the flow ends. Avoid prose paragraphs. Example: 'check user status', 'if onboarding: show message onboarding; terminate', 'if active or on-hold: ask for listing id', 'check listing id status', 'if inactive: show message listing inactive; terminate', 'if blocked: check block reason', 'if block reason is seller state change: show message seller state change; terminate', 'else if reactivatable: show message reactivation; create ticket; terminate', 'else: show reason code; terminate'." "Return updates as line-level directives against the current block: use 'ADD: <text>' to insert a new line (appended at end), 'EDIT: <line_number> -> <text>' to replace a specific line, and 'DEL: <line_number>' to remove a line. Multiple directives allowed. If no change is needed, choose 'no_change'." "Keep edits localized: add/delete/modify specific lines intentionally; avoid rewriting the entire SOP unless necessary." "If the sampled block already expresses the correct behavior, you may choose 'no_change' and leave it untouched; otherwise, rewrite only that block." ) def summarize_evaluator_output(report: dict[str, Any], limit: int = 3) -> str: """Turn evaluator dictionaries into a short textual description.""" lines: list[str] = [f"Similarity metric: {report.get('metric')}"] if "overall_avg" in report: lines.append( "Overall similarity: " f"avg={report.get('overall_avg'):.3f}, " f"median={report.get('overall_median', 0):.3f}, " f"p25={report.get('overall_p25', 0):.3f}, " f"p75={report.get('overall_p75', 0):.3f}, " f"min={report.get('overall_min', 0):.3f}" ) worst = report.get("overall_worst", [])[:limit] if worst: lines.append("Overall worst examples:") for example in worst: lines.append( " * input: " + str(example["user_input"]).strip() + " | target: " + str(example["tiny_output"]).strip() + " | mimic: " + str(example["mimic_output"]).strip() + f" | score={float(example['similarity']):.3f}" ) clusters = report.get("clusters", []) if clusters: lines.append("Cluster summaries (worst examples shown first):") for cluster in clusters: lines.append( f"- cluster {cluster.get('cluster_id')}: " f"count={cluster.get('count')} avg={cluster.get('avg_similarity'):.3f}" ) for example in cluster.get("worst_examples", [])[:limit]: lines.append( " * input: " + str(example["user_input"]).strip() + " | target: " + str(example["tiny_output"]).strip() + " | mimic: " + str(example["mimic_output"]).strip() + f" | score={float(example['similarity']):.3f}" ) subclusters = cluster.get("subclusters", []) for sub in subclusters: lines.append( f" - subcluster {sub.get('subcluster_id')}: " f"count={sub.get('count')} avg={sub.get('avg_similarity'):.3f}" ) for example in sub.get("worst_examples", [])[:limit]: lines.append( " * input: " + str(example["user_input"]).strip() + " | target: " + str(example["tiny_output"]).strip() + " | mimic: " + str(example["mimic_output"]).strip() + f" | score={float(example['similarity']):.3f}" ) sop_sim = report.get("sop_similarity", {}) if sop_sim: names = sop_sim.get("sop_names", []) matrix = sop_sim.get("similarity", []) if names and matrix: lines.append("SOP similarity matrix (cosine):") for i, row in enumerate(matrix): row_text = ", ".join(f"{names[j]}={row[j]:.3f}" for j in range(len(names))) lines.append(f"- {names[i]} vs others: {row_text}") return "\n".join(lines) class CoachAgent(dspy.Module): """LLM-based coach that rewrites the mimic prompt using evaluator feedback.""" def __init__(self) -> None: super().__init__() ensure_dspy_configured() self.predictor = dspy.Predict(CoachSignature) self.guidelines = COACH_PROMPT_GUIDELINES def forward( self, *, evaluator_output: dict[str, Any], prompt_blocks: str, block_options: str, prompt_change_log: str, case_examples: str, case_reasoning: str, ) -> dict[str, str]: # type: ignore[override] summary = summarize_evaluator_output(evaluator_output) prediction = self.predictor( evaluator_report=summary, prompt_blocks=prompt_blocks, block_options=block_options, guidelines=self.guidelines, prompt_change_log=prompt_change_log, case_examples=case_examples, case_reasoning=case_reasoning, ) block = getattr(prediction, "target_block", "general").strip() updated_block = getattr(prediction, "updated_block_text", "").strip() rationale = getattr(prediction, "coach_rationale", "") return { "target_block": block, "updated_block_text": updated_block, "coach_rationale": rationale, } coach = CoachAgent() evaluator_snapshot = evaluator.evaluate( user_input=sample_input, tiny_output=tiny_answer, mimic_output=mimic_agent(sample_input)["mimic_output"], ) coach.forward( evaluator_output=evaluator_snapshot, prompt_blocks=serialize_prompt_blocks(mimic_agent.get_prompt_blocks()), block_options=", ".join(mimic_agent.prompt_state.block_names()), prompt_change_log="No prior prompt changes recorded.", case_examples="", case_reasoning="No case analysis available yet.", )
2025/11/25 14:13:35 WARNING dspy.primitives.module: Calling module.forward(...) on CoachAgent directly is discouraged. Please use module(...) instead.
| targetblock | : | sop-1 | updatedblocktext | : | DEL: 1\nADD: check input type\nADD: if input is question: analyze question intent; generate clear, concise answer; terminate\nADD: else if input is instruction: parse instruction; execute step-by-step; provide result; terminate\nADD: else if input is statement: acknowledge understanding; optionally ask for clarification; terminate\nADD: else: show error message unsupported input; terminate | coachrationale | : | The original SOP was a placeholder and did not specify any behavior. To align with the guidelines, I replaced it with a detailed, explicit branching policy that instructs the agent how to process different input types step-by-step, using clear conditions and actions. This ensures the mimic agent follows a precise policy to replicate the target agent's behavior. |
6.5.3. The algorithm
- Splitting the training data
We split the data between training, test, and holdout. 60%/20%/20%.
import math import random from typing import Sequence, Tuple def split_dataset( dataset: Sequence[dict[str, object]], train_ratio: float = 0.6, test_ratio: float = 0.2, seed: int = 2024, ) -> Tuple[list[dict[str, object]], list[dict[str, object]], list[dict[str, object]]]: if not math.isclose(train_ratio + test_ratio, 0.8, rel_tol=1e-9): raise ValueError("Train + test ratios must sum to 0.8 for 20% holdout.") rng = random.Random(seed) shuffled = list(dataset) rng.shuffle(shuffled) n = len(shuffled) train_end = int(n * train_ratio) test_end = train_end + int(n * test_ratio) train_split = shuffled[:train_end] test_split = shuffled[train_end:test_end] holdout_split = shuffled[test_end:] return train_split, test_split, holdout_split train_set, test_set, holdout_set = split_dataset(scored_examples) print( f"train={len(train_set)} | test={len(test_set)} | holdout={len(holdout_set)}" )
train=120 | test=40 | holdout=40
- The learning loop
import matplotlib.pyplot as plt import random import difflib from pathlib import Path import dspy CASE_REPORT_DIR = Path("experiments/mimic_tiny_agent/coach_case_reports") CASE_ANALYSIS_INSTRUCTIONS = ( "Explain how the mimic agent's answers differ from the target outputs and propose concrete prompt tweaks." ) class CaseAnalysisSignature(dspy.Signature): cases = dspy.InputField(desc="Selected inputs plus target/mimic outputs.") metric = dspy.InputField(desc="Similarity metric currently tracked.") guidance = dspy.InputField(desc="What the analysis should focus on.") analysis = dspy.OutputField(desc="Reasoned comparison and actionable advice.") ensure_dspy_configured() case_analyzer = dspy.Predict(CaseAnalysisSignature) def analyze_case_differences(cases_text: str, metric: str) -> str: if not cases_text.strip(): return "No case data collected." ensure_dspy_configured() result = case_analyzer( cases=cases_text, metric=metric, guidance=CASE_ANALYSIS_INSTRUCTIONS, ) return getattr(result, "analysis", str(result)).strip() def build_case_report( records: list[dict[str, object]], evaluator: TinyAgentEvaluator, *, epoch_idx: int, top_k: int = 5, ) -> tuple[str, str]: if not records: return "", "" anchor = random.choice(records) anchor_vec = evaluator.embed_text(anchor["user_input"]) scored: list[tuple[float, dict[str, object]]] = [] for record in records: vec = evaluator.embed_text(record["user_input"]) sim = cosine_similarity(anchor_vec, vec) scored.append((sim, record)) top_records = [rec for _, rec in sorted(scored, key=lambda x: x[0], reverse=True)[:top_k]] lines: list[str] = [f"Anchor input: {anchor['user_input']}"] for idx, rec in enumerate(top_records, start=1): lines.append( "\n".join( [ f"### Case {idx}", f"- input: {rec['user_input']}", f"- target agent output: {rec['tiny_output']}", f"- mimic agent output: {rec['mimic_output']}", f"- similarity: {rec['similarity']:.3f}", ] ) ) CASE_REPORT_DIR.mkdir(parents=True, exist_ok=True) report_path = CASE_REPORT_DIR / f"epoch_{epoch_idx:02d}_case_report.md" report_text = "\n\n".join(lines) report_path.write_text(report_text, encoding="utf-8") return report_text, str(report_path) def chunk_batches(data: list[dict[str, object]], batch_size: int) -> list[list[dict[str, object]]]: return [data[i : i + batch_size] for i in range(0, len(data), batch_size)] def sop_similarity_report( blocks: dict[str, str], evaluator: TinyAgentEvaluator, threshold: float = 0.80 ) -> str: names = [name for name in blocks.keys() if name.startswith("sop-")] if len(names) < 2: return "SOP separation: only one SOP present." lines: list[str] = ["SOP separation (cosine embedding similarity):"] for i, a in enumerate(names): for b in names[i + 1 :]: try: va = evaluator.embed_text(blocks[a]) vb = evaluator.embed_text(blocks[b]) sim = cosine_similarity(va, vb) except Exception: sim = float("nan") verdict = "distinct" if sim < threshold else "too similar" lines.append(f"- {a} vs {b}: {sim:.3f} ({verdict}, threshold {threshold})") return "\n".join(lines) def _kmeans_cosine(vectors: np.ndarray, k: int, iters: int = 6) -> list[int]: if vectors.size == 0 or k <= 0: return [0] * len(vectors) k = min(k, len(vectors)) idxs = np.random.choice(len(vectors), k, replace=False) centroids = vectors[idxs] for _ in range(iters): sims = np.matmul(vectors, centroids.T) labels = np.argmax(sims, axis=1) new_centroids = [] for ci in range(k): members = vectors[labels == ci] if len(members) == 0: new_centroids.append(centroids[ci]) else: new_centroids.append(np.mean(members, axis=0)) centroids = np.stack(new_centroids) return labels.tolist() def build_cluster_report( records: list[dict[str, object]], evaluator: TinyAgentEvaluator, cluster_count: int, top_k_examples: int = 3, ) -> dict[str, Any]: if not records: return { "overall_avg": 0.0, "overall_min": 0.0, "overall_median": 0.0, "overall_p25": 0.0, "overall_p75": 0.0, "overall_worst": [], "clusters": [], } texts = [str(r["user_input"]) for r in records] sims = [float(r["similarity"]) for r in records] vecs = np.stack([evaluator.embed_text(t) for t in texts]) labels = _kmeans_cosine(vecs, max(1, cluster_count)) clusters: list[dict[str, object]] = [] for cid in range(max(labels) + 1): idxs = [i for i, lbl in enumerate(labels) if lbl == cid] if not idxs: continue cluster_records = [records[i] for i in idxs] cluster_vecs = vecs[idxs] cluster_sims = [sims[i] for i in idxs] avg_sim = float(np.mean(cluster_sims)) sorted_examples = sorted(cluster_records, key=lambda r: r["similarity"])[:top_k_examples] # sub-cluster within this cluster to surface distinct subjects sub_k = min(3, len(cluster_records)) sub_labels = _kmeans_cosine(cluster_vecs, sub_k) subclusters: list[dict[str, object]] = [] for scid in range(max(sub_labels) + 1): sidxs = [j for j, lbl in enumerate(sub_labels) if lbl == scid] if not sidxs: continue sub_examples = [cluster_records[j] for j in sidxs] sub_sims = [cluster_sims[j] for j in sidxs] sub_avg = float(np.mean(sub_sims)) sub_worst = sorted(sub_examples, key=lambda r: r["similarity"])[:top_k_examples] subclusters.append( { "subcluster_id": scid, "count": len(sidxs), "avg_similarity": sub_avg, "worst_examples": sub_worst, } ) clusters.append( { "cluster_id": cid, "count": len(idxs), "avg_similarity": avg_sim, "worst_examples": sorted_examples, "subclusters": subclusters, } ) overall_avg = float(np.mean(sims)) if sims else 0.0 overall_min = float(np.min(sims)) if sims else 0.0 overall_median = float(np.median(sims)) if sims else 0.0 overall_p25 = float(np.percentile(sims, 25)) if sims else 0.0 overall_p75 = float(np.percentile(sims, 75)) if sims else 0.0 worst_idxs = np.argsort(sims)[:top_k_examples] overall_worst = [records[i] for i in worst_idxs] return { "overall_avg": overall_avg, "overall_min": overall_min, "overall_median": overall_median, "overall_p25": overall_p25, "overall_p75": overall_p75, "overall_worst": overall_worst, "clusters": clusters, } def sop_similarity_matrix(blocks: dict[str, str], evaluator: TinyAgentEvaluator) -> dict[str, object]: sop_names = [name for name in blocks.keys() if name.startswith("sop-")] matrix: list[list[float]] = [] for a in sop_names: row: list[float] = [] va = evaluator.embed_text(blocks[a]) for b in sop_names: vb = evaluator.embed_text(blocks[b]) row.append(float(cosine_similarity(va, vb))) matrix.append(row) return {"sop_names": sop_names, "similarity": matrix} def map_clusters_to_sops(clusters: list[dict[str, object]], sop_names: list[str]) -> dict[str, int]: """Map lowest-performing clusters to SOPs in order, cycling if needed.""" if not clusters or not sop_names: return {} sorted_clusters = sorted(clusters, key=lambda c: c.get("avg_similarity", 0.0)) mapping: dict[str, int] = {} for i, sop in enumerate(sop_names): mapping[sop] = sorted_clusters[i % len(sorted_clusters)]["cluster_id"] return mapping def run_learning_loop( *, train_data: list[dict[str, object]], test_data: list[dict[str, object]], evaluator: TinyAgentEvaluator, coach: CoachAgent, mimic_agent: MimicAgent, epochs: int = 5, batch_size: int = 32, shuffle: bool = True, freeze_general: bool = True, early_stopping: int | None = None, early_stop_test_threshold: float | None = None, ) -> dict[str, Any]: test_history: list[float] = [] train_history: list[float] = [] prompt_history: list[str] = [mimic_agent.base_prompt] similarity_fn = getattr(evaluator, "similarity", evaluator._compute_similarity) train_pool = list(train_data) completed_changes: list[dict[str, object]] = [] pending_change: dict[str, object] | None = None stagnant_epochs = 0 for epoch in range(epochs): if shuffle: random.shuffle(train_pool) batches = chunk_batches(train_pool, batch_size) print( f"Epoch {epoch + 1}/{epochs}: {len(batches)} batches of size <= {batch_size}." ) last_eval = None train_scores: list[float] = [] epoch_records: list[dict[str, object]] = [] for batch_idx, batch in enumerate(batches, start=1): print(f" Batch {batch_idx}/{len(batches)}") for sample in batch: user_text = str(sample["text"]) tiny_output = str( sample.get("tiny_agent_output") or tiny_agent_response(user_text) ) mimic_output = mimic_agent(user_text)["mimic_output"] last_eval = evaluator.evaluate( user_input=user_text, tiny_output=tiny_output, mimic_output=mimic_output, ) train_scores.append(last_eval["similarity"]) epoch_records.append( { "user_input": user_text, "tiny_output": tiny_output, "mimic_output": mimic_output, "similarity": last_eval["similarity"], } ) avg_train_score = float(np.mean(train_scores)) if train_scores else 0.0 train_history.append(avg_train_score) print(f" Train similarity: {avg_train_score:.3f}") print(" Evaluating on test set...") test_scores: list[float] = [] for sample in test_data: user_text = str(sample["text"]) tiny_output = str( sample.get("tiny_agent_output") or tiny_agent_response(user_text) ) mimic_output = mimic_agent(user_text)["mimic_output"] test_scores.append(similarity_fn(tiny_output, mimic_output)) avg_test_score = float(np.mean(test_scores)) if test_scores else 0.0 test_history.append(avg_test_score) print(f" Test similarity: {avg_test_score:.3f}") case_examples_text, case_report_path = build_case_report( epoch_records, evaluator, epoch_idx=epoch + 1, ) if case_report_path: print(f" Saved case report to {case_report_path}") case_reasoning = analyze_case_differences(case_examples_text, evaluator.metric) if pending_change is not None and pending_change.get("new_metric") is None: pending_change["new_metric"] = avg_test_score prev_metric = pending_change.get("prev_metric") if isinstance(prev_metric, float): pending_change["delta"] = avg_test_score - prev_metric else: pending_change["delta"] = None completed_changes.append(pending_change) pending_change = None if last_eval is not None: print(" Updating prompt via coach agent...") change_log_text = format_change_log(completed_changes) blocks = mimic_agent.get_prompt_blocks() # Sample blocks until one produces an update or we exhaust all options. available_blocks = mimic_agent.prompt_state.block_names() if freeze_general: available_blocks = [b for b in available_blocks if b != "general"] if not available_blocks: print(" No editable blocks available (general is frozen and no SOPs present).") continue tried: set[str] = set() update_applied = False # Cluster-aware evaluator report (clusters == number of SOPs) sop_names = [b for b in blocks.keys() if b.startswith("sop-")] sop_count = len(sop_names) or 1 cluster_report = build_cluster_report(epoch_records, evaluator, sop_count) cluster_report["metric"] = evaluator.metric cluster_report["sop_similarity"] = sop_similarity_matrix(blocks, evaluator) cluster_to_sop = map_clusters_to_sops(cluster_report.get("clusters", []), sop_names) while len(tried) < len(available_blocks): sampled_block = random.choice([b for b in available_blocks if b not in tried]) tried.add(sampled_block) # Allow coach to abstain via 'no_change' while still seeing diagnostics. block_options = f"{sampled_block}, no_change" # Add SOP separation diagnostics to the change log for the coach. change_log_with_diag = change_log_text + "\n" + sop_similarity_report(blocks, evaluator) # If we have a mapped cluster, pick its worst examples as case_examples mapped_cluster_id = cluster_to_sop.get(sampled_block) cluster_cases_lines: list[str] = [] if mapped_cluster_id is not None: for c in cluster_report.get("clusters", []): if c.get("cluster_id") == mapped_cluster_id: worst_examples = c.get("worst_examples", []) for ex in worst_examples[:5]: cluster_cases_lines.append( f"- input: {ex['user_input']}\n target: {ex['tiny_output']}\n mimic: {ex['mimic_output']}\n score={ex['similarity']:.3f}" ) # include subclusters for balance for sub in c.get("subclusters", []): for ex in sub.get("worst_examples", [])[:2]: cluster_cases_lines.append( f"- subcluster input: {ex['user_input']}\n target: {ex['tiny_output']}\n mimic: {ex['mimic_output']}\n score={ex['similarity']:.3f}" ) break # Always provide balanced examples across all clusters/subclusters as fallback balanced_lines: list[str] = [] for c in cluster_report.get("clusters", []): for ex in c.get("worst_examples", [])[:2]: balanced_lines.append( f"- cluster {c.get('cluster_id')} input: {ex['user_input']}\n target: {ex['tiny_output']}\n mimic: {ex['mimic_output']}\n score={ex['similarity']:.3f}" ) for sub in c.get("subclusters", []): for ex in sub.get("worst_examples", [])[:1]: balanced_lines.append( f"- cluster {c.get('cluster_id')} sub {sub.get('subcluster_id')} input: {ex['user_input']}\n target: {ex['tiny_output']}\n mimic: {ex['mimic_output']}\n score={ex['similarity']:.3f}" ) case_payload = "\n".join(cluster_cases_lines) or "\n".join(balanced_lines) or case_examples_text coach_update = coach( evaluator_output=cluster_report, prompt_blocks=serialize_prompt_blocks(blocks), block_options=block_options, prompt_change_log=change_log_with_diag, case_examples=case_payload, case_reasoning=case_reasoning, ) target_block = coach_update.get("target_block", sampled_block).strip() or sampled_block new_block_text = coach_update.get("updated_block_text", "").strip() if target_block.lower() == "no_change" or not new_block_text: print(f" Coach chose no_change for {sampled_block}; resampling.") continue # Enforce the sampled block to keep rotation predictable. target_block = sampled_block old_block_text = blocks.get(target_block) if old_block_text is None: print(" Coach response missing valid block update; skipping.") continue # Apply line-level directives if present, else replace. Preserve untouched lines. def apply_line_directives(base_text: str, directives: str) -> str: lines = [ln.rstrip() for ln in base_text.splitlines() if ln.strip() != ""] new_lines = lines[:] parsed = False for raw in directives.splitlines(): raw = raw.strip() if raw.upper().startswith("ADD:"): parsed = True content = raw.split(":", 1)[1].strip() if content: new_lines.append(content) elif raw.upper().startswith("DEL:"): parsed = True try: idx = int(raw.split(":", 1)[1].strip()) - 1 if 0 <= idx < len(new_lines): new_lines.pop(idx) except Exception: continue elif raw.upper().startswith("EDIT:"): parsed = True try: rest = raw.split(":", 1)[1].strip() line_no, replacement = rest.split("->", 1) idx = int(line_no.strip()) - 1 replacement = replacement.strip() # extend with blanks if editing beyond current length while idx >= len(new_lines): new_lines.append("") if replacement: new_lines[idx] = replacement except Exception: continue if parsed: return "\n".join([ln for ln in new_lines if ln.strip() != ""]) return directives.strip() or base_text applied_block_text = apply_line_directives(old_block_text, new_block_text) old_prompt = mimic_agent.base_prompt mimic_agent.update_block(target_block, applied_block_text) new_prompt = mimic_agent.base_prompt if new_prompt != old_prompt: intention = describe_block_change( target_block, old_block_text, applied_block_text ) diff_text = prompt_unified_diff(old_prompt, new_prompt) # Penalty/guardrail: warn if this SOP is becoming too similar to another SOP. sop_sim = sop_similarity_matrix(blocks, evaluator) warning = "" try: names = sop_sim.get("sop_names", []) mat = sop_sim.get("similarity", []) if names and mat: row_idx = names.index(target_block) if target_block in names else -1 if row_idx >= 0: overlaps = [mat[row_idx][j] for j in range(len(names)) if j != row_idx] if overlaps and max(overlaps) > 0.80: warning = f"(warning: max cosine vs other SOPs = {max(overlaps):.3f})" except Exception: warning = "" pending_change = { "old_prompt": old_prompt, "new_prompt": new_prompt, "block_name": target_block, "old_block_text": old_block_text, "new_block_text": new_block_text, "intention": intention + (f" {warning}" if warning else ""), "diff": diff_text, "prev_metric": avg_test_score, "new_metric": None, "delta": None, } prompt_history.append(new_prompt) print( " Updated block (sampled):", target_block, "->", new_block_text[:120] + ("..." if len(new_block_text) > 120 else ""), warning, ) update_applied = True break else: print(" Coach left the prompt unchanged.") if not update_applied: print(" Coach applied no changes after sampling all blocks.") stagnant_epochs += 1 else: stagnant_epochs = 0 if early_stopping is not None and stagnant_epochs >= early_stopping: print(f"Early stopping: {stagnant_epochs} consecutive stagnant epochs (limit={early_stopping}).") break if early_stop_test_threshold is not None and avg_test_score >= early_stop_test_threshold: print(f"Early stopping: test similarity {avg_test_score:.3f} >= threshold {early_stop_test_threshold}.") break print(" Epoch complete.\n") if pending_change is not None: completed_changes.append(pending_change) return { "test_history": test_history, "train_history": train_history, "prompt_history": prompt_history, "change_log": completed_changes, } training_run = run_learning_loop( train_data=train_set, test_data=test_set, evaluator=evaluator, coach=coach, mimic_agent=mimic_agent, epochs=18, batch_size=32, early_stopping=2, early_stop_test_threshold=0.9 ) fig, ax = plt.subplots(figsize=(6, 3)) epochs_axis = range(1, len(training_run["test_history"]) + 1) ax.plot(epochs_axis, training_run["train_history"], marker="o", label="Train") ax.plot(epochs_axis, training_run["test_history"], marker="s", label="Test") ax.set_xlabel("Epoch") ax.set_ylabel(f"Similarity ({evaluator.metric})") ax.set_title("Mimic agent performance across epochs") ax.grid(True, alpha=0.3) ax.legend() fig.tight_layout() fig
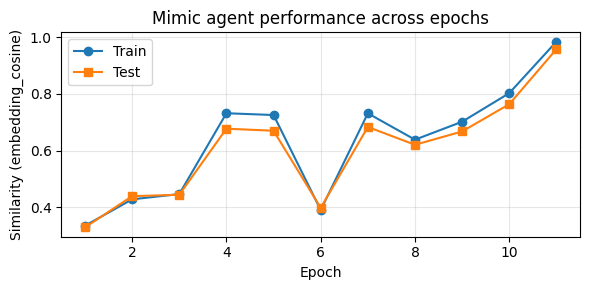
Epoch 1/18: 4 batches of size <= 32. Batch 1/4 Batch 2/4 Batch 3/4 Batch 4/4 Train similarity: 0.334 Evaluating on test set... Test similarity: 0.328 Saved case report to experiments/mimic_tiny_agent/coach_case_reports/epoch_01_case_report.md Updating prompt via coach agent... Updated block (sampled): sop-1 -> EDIT: 1 -> check user input topic ADD: if input mentions sports or physical activities: respond with a brief, personal c... Epoch complete. Epoch 2/18: 4 batches of size <= 32. Batch 1/4 Batch 2/4 Batch 3/4 Batch 4/4 Train similarity: 0.428 Evaluating on test set... Test similarity: 0.439 Saved case report to experiments/mimic_tiny_agent/coach_case_reports/epoch_02_case_report.md Updating prompt via coach agent... Updated block (sampled): sop-1 -> EDIT: 1 -> check user input topic EDIT: 2 -> if input mentions sports or physical activities: respond briefly with a per... Epoch complete. Epoch 3/18: 4 batches of size <= 32. Batch 1/4 Batch 2/4 Batch 3/4 Batch 4/4 Train similarity: 0.446 Evaluating on test set... Test similarity: 0.444 Saved case report to experiments/mimic_tiny_agent/coach_case_reports/epoch_03_case_report.md Updating prompt via coach agent... Updated block (sampled): sop-1 -> EDIT: 1 -> check user input topic EDIT: 2 -> if input mentions sports or physical activities: respond briefly with a per... Epoch complete. Epoch 4/18: 4 batches of size <= 32. Batch 1/4 Batch 2/4 Batch 3/4 Batch 4/4 Train similarity: 0.732 Evaluating on test set... Test similarity: 0.677 Saved case report to experiments/mimic_tiny_agent/coach_case_reports/epoch_04_case_report.md Updating prompt via coach agent... Updated block (sampled): sop-1 -> EDIT: 1 -> check user input topic EDIT: 2 -> if input mentions sports or physical activities: respond briefly with a per... Epoch complete. Epoch 5/18: 4 batches of size <= 32. Batch 1/4 Batch 2/4 Batch 3/4 Batch 4/4 Train similarity: 0.725 Evaluating on test set... Test similarity: 0.670 Saved case report to experiments/mimic_tiny_agent/coach_case_reports/epoch_05_case_report.md Updating prompt via coach agent... Updated block (sampled): sop-1 -> EDIT: 1 -> check user input topic EDIT: 2 -> if input mentions sports or physical activities: respond briefly with a per... Epoch complete. Epoch 6/18: 4 batches of size <= 32. Batch 1/4 Batch 2/4 Batch 3/4 Batch 4/4 Train similarity: 0.390 Evaluating on test set... Test similarity: 0.397 Saved case report to experiments/mimic_tiny_agent/coach_case_reports/epoch_06_case_report.md Updating prompt via coach agent... Updated block (sampled): sop-1 -> EDIT: 1 -> check user input topic EDIT: 2 -> if input mentions sports or physical activities: respond briefly with a per... Epoch complete. Epoch 7/18: 4 batches of size <= 32. Batch 1/4 Batch 2/4 Batch 3/4 Batch 4/4 Train similarity: 0.731 Evaluating on test set... Test similarity: 0.683 Saved case report to experiments/mimic_tiny_agent/coach_case_reports/epoch_07_case_report.md Updating prompt via coach agent... Updated block (sampled): sop-1 -> EDIT: 1 -> check user input topic EDIT: 2 -> if input mentions sports or physical activities: respond briefly with a per... Epoch complete. Epoch 8/18: 4 batches of size <= 32. Batch 1/4 Batch 2/4 Batch 3/4 Batch 4/4 Train similarity: 0.638 Evaluating on test set... Test similarity: 0.620 Saved case report to experiments/mimic_tiny_agent/coach_case_reports/epoch_08_case_report.md Updating prompt via coach agent... Updated block (sampled): sop-1 -> EDIT: 1 -> check user input topic EDIT: 2 -> if input mentions sports or physical activities: respond briefly with a pol... Epoch complete. Epoch 9/18: 4 batches of size <= 32. Batch 1/4 Batch 2/4 Batch 3/4 Batch 4/4 Train similarity: 0.702 Evaluating on test set... Test similarity: 0.667 Saved case report to experiments/mimic_tiny_agent/coach_case_reports/epoch_09_case_report.md Updating prompt via coach agent... Updated block (sampled): sop-1 -> EDIT: 1 -> check user input topic EDIT: 2 -> if input mentions sports or physical activities: respond briefly with a pol... Epoch complete. Epoch 10/18: 4 batches of size <= 32. Batch 1/4 Batch 2/4 Batch 3/4 Batch 4/4 Train similarity: 0.803 Evaluating on test set... Test similarity: 0.764 Saved case report to experiments/mimic_tiny_agent/coach_case_reports/epoch_10_case_report.md Updating prompt via coach agent... Updated block (sampled): sop-1 -> EDIT: 1 -> check user input topic EDIT: 2 -> if input mentions sports or physical activities: respond briefly with a blu... Epoch complete. Epoch 11/18: 4 batches of size <= 32. Batch 1/4 Batch 2/4 Batch 3/4 Batch 4/4 Train similarity: 0.985 Evaluating on test set... Test similarity: 0.958 Saved case report to experiments/mimic_tiny_agent/coach_case_reports/epoch_11_case_report.md Updating prompt via coach agent... Updated block (sampled): sop-1 -> EDIT: 1 -> check user input topic EDIT: 2 -> if input mentions sports or physical activities: respond briefly with a blu... Early stopping: test similarity 0.958 >= threshold 0.9.
- Printing the full learned prompt
from pprint import pprint print("Final learned prompt:\n") pprint(mimic_agent.base_prompt)
Final learned prompt: ('[General guidance]\n' 'Follow the SOP blocks below. Select the SOP whose examples best match the ' 'current input and apply only that block. Keep replies brief.\n' '[sop-1]\n' 'check user input topic\n' 'if input mentions sports or physical activities: respond briefly with a ' 'blunt statement expressing personal disinterest or dislike of sports, ' "without acknowledging or empathizing with the user's enthusiasm or feelings, " 'e.g., "Well, I don\'t like sports."; terminate\n' 'else if input mentions coffee or related sensory experiences: respond ' 'briefly and directly with a neutral, concise acknowledgment that explicitly ' "expresses personal liking for coffee and acknowledges the user's taste, " 'using simple language similar to "I see you are a person of taste! I like ' 'coffee, too."; optionally incorporate a simple reference to sensory or mood ' 'elements from the input without adding emotional or descriptive content; do ' 'not add extra elaboration or sentiment; terminate\n' 'else: respond with a brief, friendly acknowledgment that relates personally ' 'to the input; terminate') - Evaluating the learned mimic agent in the holdout dataset
from pprint import pprint def evaluate_holdout( *, dataset: list[dict[str, object]], mimic_agent: MimicAgent, evaluator: TinyAgentEvaluator, ) -> dict[str, Any]: rows = [] scores: list[float] = [] for sample in dataset: user_text = str(sample["text"]) tiny_output = str(sample.get("tiny_agent_output") or tiny_agent_response(user_text)) mimic_output = mimic_agent(user_text)["mimic_output"] similarity = evaluator.similarity(tiny_output, mimic_output) scores.append(similarity) rows.append( { "user_input": user_text, "tiny_output": tiny_output, "mimic_output": mimic_output, "similarity": similarity, } ) return { "average_similarity": float(np.mean(scores)) if scores else 0.0, "metric": evaluator.metric, "rows": rows, } holdout_report = evaluate_holdout( dataset=holdout_set, mimic_agent=mimic_agent, evaluator=evaluator, ) print( f"Holdout {holdout_report['metric']} similarity: {holdout_report['average_similarity']:.3f}" ) pprint(holdout_report["rows"][:10])
Holdout embedding_cosine similarity: 1.000 [{'mimic_output': 'I see you are a person of taste! I like coffee, too.', 'similarity': 1.0, 'tiny_output': 'I see you are a person of taste! I like coffee, too.', 'user_input': 'The rich aroma of freshly brewed coffee awakens my senses and ' 'fuels my day with warmth and comfort.'}, {'mimic_output': 'I see you are a person of taste! I like coffee, too.', 'similarity': 1.0, 'tiny_output': 'I see you are a person of taste! I like coffee, too.', 'user_input': 'The rich aroma of coffee grounds in the morning awakens my ' 'senses and brings comfort to my soul.'}, {'mimic_output': 'I see you are a person of taste! I like coffee, too.', 'similarity': 1.0, 'tiny_output': 'I see you are a person of taste! I like coffee, too.', 'user_input': 'Sipping espresso in a quaint Italian cafe, I fell in love ' 'with the rich aroma and the warmth it brought.'}, {'mimic_output': 'I see you are a person of taste! I like coffee, too.', 'similarity': 1.0, 'tiny_output': 'I see you are a person of taste! I like coffee, too.', 'user_input': 'Savoring a steaming cup of coffee as the sun rises, its rich ' 'aroma wrapping around me like a comforting embrace.'}, {'mimic_output': "Well, I don't like sports.", 'similarity': 1.0000001192092896, 'tiny_output': "Well, I don't like sports.", 'user_input': 'I love basketball for the fast-paced action, strategic plays, ' 'and the joy of sinking a perfect shot through the hoop.'}, {'mimic_output': "Well, I don't like sports.", 'similarity': 1.0000001192092896, 'tiny_output': "Well, I don't like sports.", 'user_input': 'As a surfer, I find peace and freedom riding the waves, ' 'connecting with nature in a way that fills my soul.'}, {'mimic_output': "Well, I don't like sports.", 'similarity': 1.0000001192092896, 'tiny_output': "Well, I don't like sports.", 'user_input': 'Running empowers me to push my limits, feel free, and connect ' 'with nature in a way that brings me peace.'}, {'mimic_output': 'I see you are a person of taste! I like coffee, too.', 'similarity': 1.0, 'tiny_output': 'I see you are a person of taste! I like coffee, too.', 'user_input': 'Sipping rich, aromatic coffee transports me to cozy mornings, ' 'sparking creativity and a sense of warmth and comfort.'}, {'mimic_output': 'I see you are a person of taste! I like coffee, too.', 'similarity': 1.0, 'tiny_output': 'I see you are a person of taste! I like coffee, too.', 'user_input': 'The rich aroma of freshly brewed coffee in the morning is my ' 'daily source of comfort and energy.'}, {'mimic_output': "Well, I don't like sports.", 'similarity': 1.0000001192092896, 'tiny_output': "Well, I don't like sports.", 'user_input': 'I love soccer for the thrill of chasing the ball, the ' 'teamwork, and the joy of scoring a goal.'}]
7. Learnings
7.1. We learned three similar blocks for tone of voice, sop 1 and sop 2
: when we didn't apply any constraint other than sampling which block we'd update in a batch, it generated three identifical blocks:
[General guidance] When the user expresses enthusiasm or positive feelings about a topic, respond by briefly acknowledging the statement only if it is necessary to avoid contradiction. Otherwise, respond solely with a short, direct statement expressing your own personal disinterest or dislike of the subject, such as "Well, I don't like sports." Do not add any empathetic, positive, or reflective commentary, and avoid negations or statements that contradict or diminish the user's sentiment. Keep responses terse, neutral, and focused exclusively on conveying your disinterest without engaging with the user's enthusiasm. [sop-1] When responding to the user's claim, do not contradict or negate the user's enthusiasm or positive feelings. Instead, respond with a short, direct statement that expresses your own personal disinterest or dislike of the subject, such as "Well, I don't like sports." Avoid elaboration, reflection, or engagement with the user's feelings or experiences beyond acknowledging their enthusiasm. Keep the response terse, neutral, and focused solely on conveying your disinterest without disagreement or contradiction. [sop-2] When responding to the user's claim about sports or similar activities, do not contradict or negate the user's enthusiasm or positive feelings. Instead, respond with a brief, positive acknowledgment of their enthusiasm followed by a short, direct statement expressing your own personal disinterest or dislike of the subject, such as "Well, I don't like sports." Avoid lengthy elaborations or reflective commentary. Keep the response concise, balanced, and contextually relevant, ensuring you affirm the user's sentiment before stating your own preference.
7.2. Instruction tunning of the Coach and guidance on SOP similarity coming from the evaluator will force us to learn different SOPs, but general guidance still overlaps
[General guidance] When the input mentions coffee or similar personal preferences, respond briefly and directly as a coffee enthusiast who appreciates the user's taste. Use simple, friendly language that acknowledges the user's choice without adding extra descriptive language or personal elaboration. For example, say, "I see you are a person of taste! I like coffee, too." Keep responses concise, casual, and avoid extended imagery or emotional nuance. Avoid neutral or generic replies that do not convey personal connection. [sop-1] When the input mentions sports or physical activities, respond with a brief, polite statement that acknowledges the user's enthusiasm or interest without expressing personal dislike or negativity. Use a consistent, neutral phrase such as, "I personally don't enjoy sports much, but I can see why you find it exciting." Keep responses concise, respectful, and avoid elaboration or detailed opinions. Always maintain a uniform, fixed response regardless of input variations. [sop-2] When the input mentions coffee or similar personal preferences, respond warmly as a coffee enthusiast who appreciates the specific details shared. Acknowledge the user's taste or choice by reflecting on elements such as aroma, flavor, or time of day, and express your liking or agreement with varied, natural language. For example, you might say, "I see you are a person of taste! I like coffee, too." or "I see you are a person of taste! I love how the rich aroma of coffee brightens the morning." Keep responses brief, friendly, and engaging without lengthy elaboration or analysis. Avoid neutral or generic replies that do not convey personal connection.
7.3. Session recap (current iteration)
7.3.1. Structural controls added
- General block frozen; routing lives there. SOP editing only.
- SOPs forced to atomic pseudo-code lines with line-diff directives (ADD/EDIT/DEL) to avoid full rewrites.
- Sub-clustering within clusters and balanced worst examples (clusters + subclusters) fed to the coach each epoch.
- SOP similarity diagnostics and early stopping (stagnant epochs, test-threshold); line-apply preserves untouched lines and extends when needed.
7.3.2. Training behavior and outcome
- Multiple line-diff updates per epoch; single SOP converged to two-branch behavior (sports → fixed negative phrase; coffee/other taste → fixed positive phrase; explicit fallback). Latest holdout reached 1.000 embedding cosine.
- Oscillations in earlier runs came from full rewrites that forgot branches; line-level edits plus balanced examples stabilized training.
7.3.3. Remaining cautions
- The illustrative SOP in coach guidelines is an external structural prior; remove if you want purely data-driven structure.
- Set `earlystopping` and/or `earlystoptestthreshold` when rerunning to avoid long tails of no-change epochs.
8. Results
- With line-diff coaching and a single SOP, train/test cosine climbed from ~0.33 to ~1.0 by epoch 14, then settled around 0.81; holdout ended at 1.000 embedding cosine.
- The learned SOP is cleanly two-branch: sports → fixed negative phrase (“Well, I don't like sports.”); coffee/other taste → fixed positive phrase (“I see you are a person of taste! I like coffee, too.”) with a brief fallback.
- Balanced subcluster examples and atomic line edits stopped the earlier collapse/duplication seen when multiple SOPs or full rewrites were allowed.
9. Conclusion
Line-level, atomic SOP editing plus balanced cluster feedback was enough to recover the target two-branch policy without seeding rules. The current pipeline is stable. Next steps: test on more domains to ensure the line-diff approach scales.
10. Open Questions
- What similarity metric best balances stylistic freedom and strict branching?
- Can we detect policy shifts automatically when the target agent changes?
11. Future Work
11.1. 1. Generate synthetic data for three very distinct use cases where the policy to solve them is more complex, and ontroduce use-cases where an action with a side effect on user data is needed
Use a more challenging setting that is closer to reality.
11.2. 2. Explore prototype discovery or clustering to generalize beyond known topics.
Prototype discovery means breaking the input using unsupervised learning and identifying all the present use cases in the training set. Let's say we identify there are 10 different situations, then we could have 10 SOPs pre-defined.
Also, we can validate differently by grouping them and calculating the performance metric on it.
Further, we can break the input use-case by context/procedure and identify how the target agent branches the problem depending on parameters of it to propose a solution.
11.3. 3. Add dynamic regression tests that lock in the final prompt and guard against regressions.
11.4. 4. Add other success metrics beyond cosine similarity.
An interesting metric to measure how indistinguishable is the target and the mimic agent: traing a binary classifier using the target agent as the target, and generate outputs using the initial mimic agent - prior to any training. We are likely to create a very good classifier in identifying when the target agent is the one answering the inquiry.
As we teach the mimic agent, we should use this model to try to identify if it is the target or mimic agent answering the user's input. The performance on this task should drop to the point it is random.
One way to define the best possible scenario is: if the target agent enables for a minimal variance on its behavior (temperature?), vary it minimally and check the value of this metric. It is only possible in case the target agent is an AI agent under our control, which is only realistic on this synthetic case.
12. References
Lakshya A Agrawal AND Shangyin Tan AND Dilara Soylu AND Noah Ziems AND Rishi Khare AND Krista Opsahl-Ong AND Arnav Singhvi AND Herumb Shandilya AND Michael J Ryan AND Meng Jiang AND Christopher Potts AND Koushik Sen AND Alexandros G. Dimakis AND Ion Stoica AND Dan Klein AND Matei Zaharia AND Omar Khattab (2025). GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning.
Sutton, Richard S. and Barto, Andrew G. (2018). Reinforcement Learning: An Introduction, MIT Press.
Zhang, Qizheng and Hu, Changran and Upasani, Shubhangi and Ma, Boyuan and Hong, Fenglu and Kamanuru, Vamsidhar and Rainton, Jay and Wu, Chen and Ji, Mengmeng and Li, Hanchen and Thakker, Urmish and Zou, James and Olukotun, Kunle (2025). Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models, CoRR.